
expand和unsqueeze在一些情况使用的含义
情况一
input:
1 | import torch |
output:
1 |
|
换种说法就是:
a: [B, L, F]
b: [B, L, F, F]
每个字对应一个[F, F]的矩阵
这个矩阵的第i行第j列的元素的含义是:上一时刻tag为i, 这一时刻tag为j的分数。比如应用到一阶马尔可夫相关的模型中。
情况二(这种情况没真实测试过,需谨慎对待)
1 | # b 代表的是: sequence length: 3 * 3 |
即这个长度为3的句子形成一个首尾的矩阵,最后一维代表相关的概率。
比如在嵌套ner任务中,
| 我 | 爱 | 北 | 京 | |
|---|---|---|---|---|
| 我 | ||||
| 爱 | ||||
| 北 | 0.03 | 0.02 | 0.05 | 0.9 |
| 京 |
我最敬爱的老婆
昨晚10点多突然急性肠炎,躺在床上无心睡眠。前天就有相应症状了,只是没那么明显也没在意。
老婆看我难受,就开始拿手机在网上百度,拉肚子应该吃什么药,氯化钠盐水、抗生素什么的。
我说小区外药店应该还开着吧,老婆遂起床跑出去给我买药。随后我起床上厕所给她发消息说我在网上买,你赶紧回来吧。11点多吃了肠炎宁就睡了。
凌晨1点多肚子咕噜咕噜闹肚子,去了厕所,喝了自创的盐糖水,喝了两口瞬间呕吐。我瞬间觉得不能不看了。
老婆迷迷糊糊的从卧室出来,说你又拉肚子了。我嗯了下。她揉着眼说我陪你去医院吧。老婆拿着上衣,搜了急诊,离住的地方1公里多。路上走着准备打车,可惜没有一辆出租车停,老婆说应该人家是换班了。
到了医院,扫了健康码,登记病情,抽血等待40分钟,1楼查看抽血报告、交钱,2楼拿药,4楼挂水。
终于坐着挂吊水了,前前后后等了那么久。
期间有喝醉酒的和他女朋友发着脾气般的打情骂俏。
我老婆直接怼了回去,能不能小点声,人家还得睡觉呢。
哈哈哈,再也不怂了。
拿着手机又去刷吴亦凡的瓜去了~
觉得这个时刻应该记录下来,遂拍了几张照片,老婆的照片就不放出来了。



等我拍了那几张照片翻回来看时,突然觉得冥冥之中遇到我老婆早已缘分注定,科学的尽头便是神学,更坚定了我的想法。
能遇到我老婆是我人生中最大的福气吧。
ubuntu16.04多GPU风扇转速调整
最近闲置出来两块1080ti GPU,内心那叫一个激动哇,虽然有些老,另外训练时转速提不上去,此次就解决这个问题。
方法一(个人只在单GPU上实验成功)
1. 生成xorg.conf
如果:
cannot stat /etc/x11/xorg.conf no such file or directory
1 | # 生成这个文件 |
2. vim /etc/x11/xorg.conf
添加Option "Coolbits" "4"到device nvidia 里面.如果有多个就每个都add。
3. reboot
4.nvidia-settings
打开nvidia-settings软件,然后调风扇转速即可。
方法二
使用coolgpus
1. 关闭图形化界面
1 | systemctl stop lightgdm && systemctl lightgdm disable lightgdm |
2. 使用coolgpus
1 | [Unit] |
1 | sudo systemctl enable coolgpus |
个人建议
如果使用coolgpus的时候先确保可以正常使用,然后再添加到systemctl里面去。
1 | systemctl stop lightgdm |
如果可以了再后续操作。
lstm使用示例
注意,本文代码来自于plm-nlp-code。
学习任何模型都需要一个简单可行的例子进行说明,我会基于plm-nlp-code的代码进行说明lstm在序列标注和句子极性二分类两个例子的应用。
序列标注
参考文件lstm_postag.py.
1. 加载数据
1 | #加载数据 |
其中load_treebank代码:
1 | def load_treebank(): |
加载后可以看到,train_data和test_data都是list,其中每一个sample都是tuple,分别是input和target。如下:
1 | train_data[0] |
2. 数据处理
1 |
|
3. 模型部分
1 | class LSTM(nn.Module): |
其中有几个地方可能需要注意的:
- pack_padded_sequence和pad_packed_sequence
因为lstm为rnn模型,样本输入不一定是等长的,那么torch提供了这两个函数进行统一处理,length告诉lstm,等超过length时这个样本后面pad进来的就不再计算了。
1 | from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence |
- lstm输出
hidden, (hn, cn)分别表示每个timestep的输出,最后一个时刻的每层输出,cn表示保存c的值。
所以可以看到,序列标注会用到每个timestep的输出来表示每个token。
- F.log_softmax和损失函数计算
如果看源码较多的情况下,你会发现log_softmax或者softmax会和CrossEntropyLoss出现在一起,这里很简单理解,因为CrossEntropyLoss由两个函数组成,log_softmax和NLLLoss,log_softmax或者softmax是做归一化,由分数转成概率,log_softmax是平滑。NLLLoss负责取target index对应的logits score,然后除以总分。目的使之最大。
3. 训练
1 | #训练过程 |
这部分没啥好说的了,log_probs为三维矩阵,比如torch.Size([32, 58, 47]),表示batch_size=32,seq_length=58,一共47个tags。
推理部分就是argmax取其最大的tag index,可以看:
1 | acc = 0 |
句子极性二分类
这个名字自己起的,任务目标具体就是对输入句子做二分类。
1. 加载数据
1 | def load_sentence_polarity(): |
关于数据格式:
1 | train_data[321] |
label一共有两个,0和1,所以为二分类。
2. 有趣的点
整个训练过程貌似和上例没什么不同,但是可以举几个比较有意思的地方。
- 关于二分类使用CrossEntropyLoss还是BCELoss
这两者本质是一样的,BCELoss就是CrossEntropyLoss的特例。你可以看loss.py。
BCEWithLogitsLoss和BCELoss的区别就是一个需要用sigmoid一个不需要。
你可以尝试改动这个代码,将作者使用到的log_softmax和NLLLoss改成使用sigmoid和BCELoss。
- lstm中hn的输出
既然hn表示timestep的最后一个时刻的输出,那么我们也有理由相信,最后一个时刻的feature可以代表整个句子的feature。
那么就需要关注下hn的输出具体是什么样子了。
源码输出example比如:
1 | hn.shape |
其中1是因为num_layers为1,又不是双向lstm,所以为1。
而如果改成双向lstm,bidirectional=True,那么,
1 | hn.shape |
如果num_layers为3,那么:
1 | hn.shape |
到这里我们就要理解下他输出的含义了?
他表示一共有6个层,即3个双向lstm,而双向的实现,就是正向计算一次,反向再计算一次,即[::-1],那么一共6层。
整个模型更改如下:
1 | class LSTM(nn.Module): |
python bdist_wheel
利用cython进行编译成库.
1. setup.py
1 | # coding: utf-8 |
2. build
1 | python setup.py build_ext --inplace |
3. 结论
通过这种方式编译成一个库,正常情况下无法查看源码。
在开发过程中,IDE无法自动导入,就正常打包方便开发同学调试、使用,而在生产环境使用2方式进行编译成一个安装包,开发替换一下安装包路径即可。
pytorch学习率调整
keras
在keras中,比如动态调整学习率,可以:
1 |
|
lr_scheduler
在pytorch中,提供了torch.optim.lr_scheduler
1. StepLR
1 | # -*- coding: utf8 -*- |
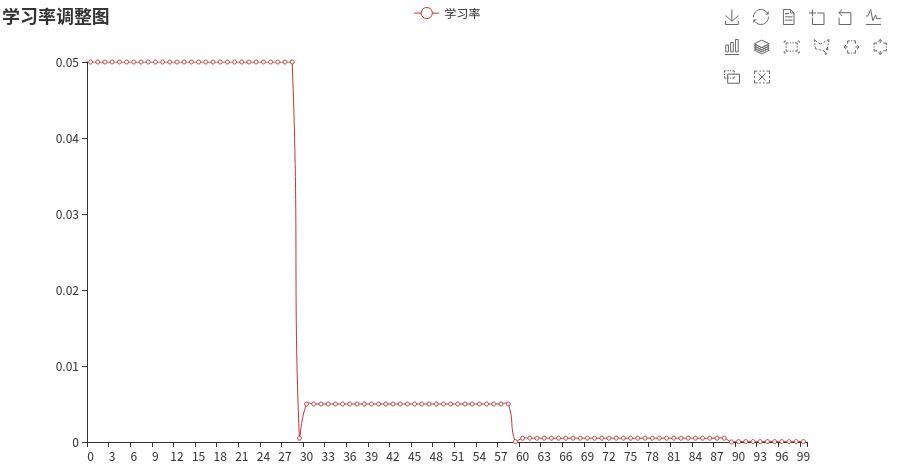
2. MultiStepLR
1 |
|
这个可以设置区间,在30 ~ 80 为一个学习率
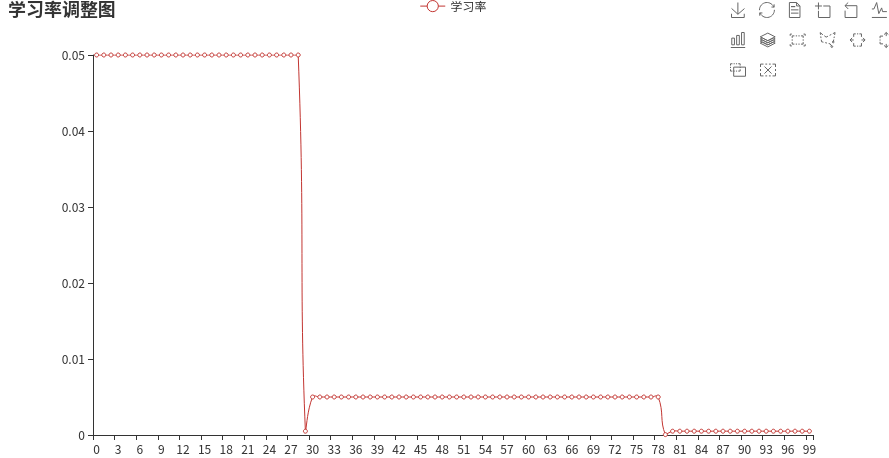
3. ExponentialLR
1 | scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9) |
指数衰减
transformers库
在transformers库中,也提供了一些,比如:
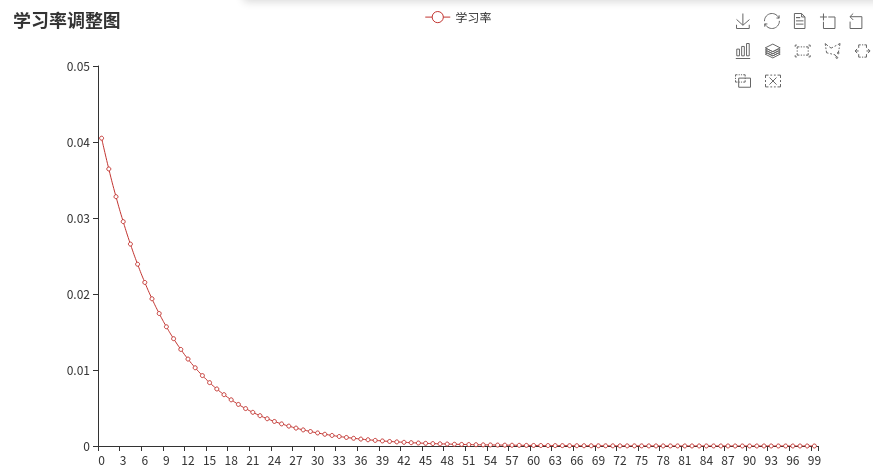
1. get_linear_schedule_with_warmup
学习率预热
1 | num_warmup_steps = 0.05 * len(train_dataloader) * epochs |
1 | optimizer = optim.Adam(params=model.parameters(), lr=1e-3) |
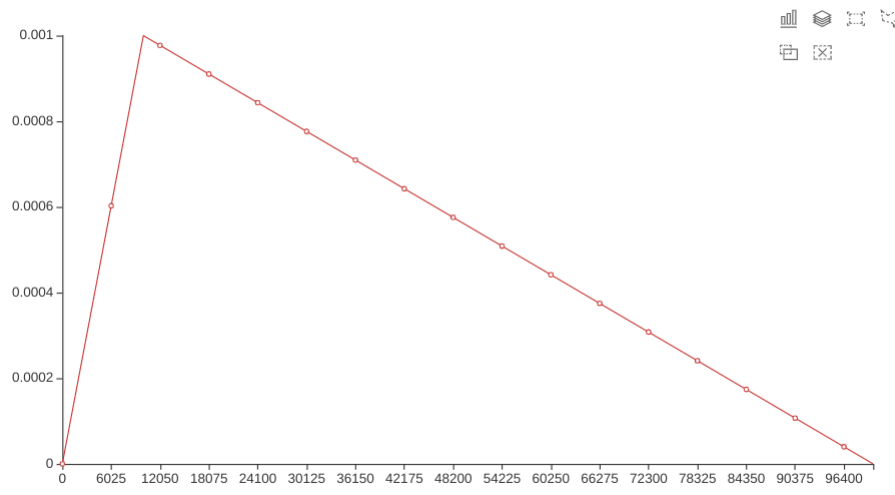
学习率先不断上升,然后再不断减小。
在预热期间,学习率从0线性增加到优化器中的初始lr。随后线性降低到0
批次数据处理
在数据处理里,常使用DataSet和DataLoader,关于具体使用此处不介绍,对于每一个batch_size里的数据来讲,
一般数据是shuffle=True,即表示打乱顺序,能够使数据更无规律和更为随机。但是如果对于数据样本不定长的情况或者说分布不均匀的情况下,
要使其定长,做法就是pad到一个固定长度,如果长短分布差距大呢??
比如:
1 | example1: 我有一个小摩托,我从来也不急,骑着我的小摩托,从此把它骑。 |
如果将example2和example1pad到一个固定长度,pad太多。(虽然你可以扯进来mask,但是要在model的每一layer都要设置mask,关于mask此处忽略。)
如何在一个batch_size样本里面使数据分布更为接近?
kmean algo for clustering the feature by length.
kmeans等聚类算法就可以辅助解决,以每条数据的长度为依据。
1 |
|
这样使用的话,那么batch_size就木有啥子用处了,有可能一个batch样本量为1,也有可能为设置的上限。
但是转念一想,其实也可以不用如此复杂,直接sorted by length也是可以的嘛,具体解释就忽略了。
数据增强
图像常见数据增强有翻转,旋转,缩放比例等不同的transforms。
对于文本,可以增加噪声干扰,也可以通过添加slide window(此处重点,嘿嘿。)
举个简单例子描述下滑动窗口。
1 | a = [1,2,3,4,5] |
但是在某些训练结果下,其作用貌似并不大,反正可以尝试。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true