介绍
LightRAG跟GraphRAG类似,是通过将文档处理成知识图谱,然后针对知识图谱进行检索的一套实现,所以接下来我们大概看下其流程。
知识图谱生成
这里和GraphRAG基本保持一致,通过prompt来进行生成。
1 |
|
显而易见在一个这么长的prompt里面再插入文本,会导致LLM理解能力变弱,一个特征是提取的relation会更少,所以它这里又进行了二次提取。
1 | MANY entities and relationships were missed in the last extraction. Please find only the missing entities and relationships from previous text. |
即prompt1 + LLM output + prompt2(上面这个)来提取更多entity和relations.
至此完成知识图谱的构建。
我觉得腾讯开源的WeKnora提示词也许会更好,实体是实体,关系是关系。
同时这里也暴露出来些许问题:
- 知识图谱构建效果,有没有漏提错提三元组。
- 实体进行融合。
整体来讲,知识图谱构建效果,将影响后续的使用效果。
查询
作者这里提供了Native Search、Local Search、Global Search和Hybrid Search四种查询方式,由于Native Search是原始chunk查询方式,Hybrid Search是Local和Global的融合,所以我们接下来单看这两块。
用户query解析
LightRAG将对用户query解析分成两块,即Low Keywords和High Keywords,这两者区别在哪,即前者更注重具体实体,后者更关注全局表达。对应代码如下:
1 |
|
下面是他的提示词:
1 | ---Role--- |
 |
 |
|---|---|
| ChatGPT结果 | DeepSeek结果 |
新能源车辆甚至是新能源难道不应该在low keywords里么,所以这里第一个问题在于LLM对其的理解能力将影响下游查询效果。当然如果将上述prompt更改成中文我觉得DS也会更好。
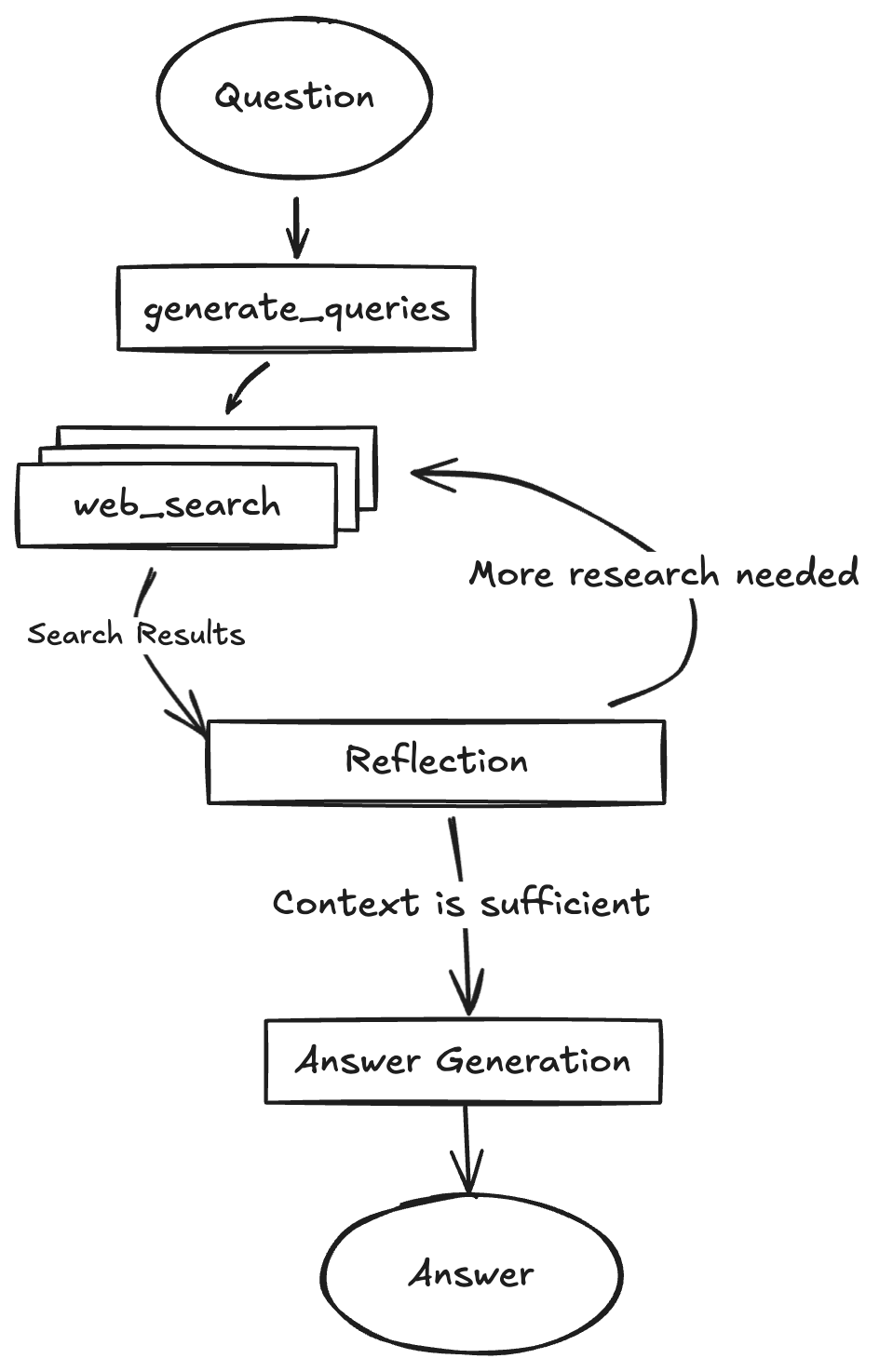
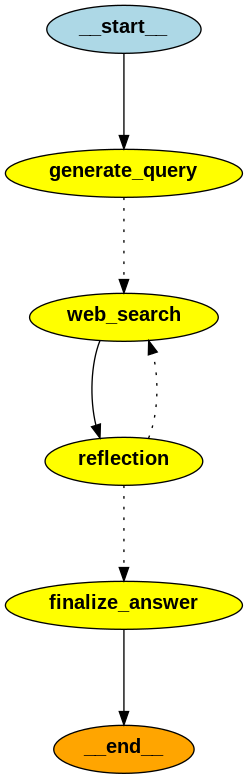
接下来根据搜索模式来走对应流程,如下图,不同模式最终都会返回entities和relations,接下来看这两种不同模式下的搜索策略。

Local Search
entities:通过low keywords对entities vector库进行召回。即topK(cos_sim(get_embed('安徽芜湖, 奇瑞, 奇瑞新能源汽车, 北美'), entities vector db))。
relations: 拿到上述entities,接着获取一跳节点所组成的边。即[graph.list_edges(node) for node in entities]。
接下来就是排序,entities根据其degree进行排序,relations根据src degree + tgt degree和edge weight(通过LLM在生成知识图谱时获取)进行综合rank。
Global Search
relations: 通过high keywords对relations vector库进行召回。即topK(cos_sim(get_embed('新能源汽车, 销售量, 北美市场'), relations vector db))。
entities:根据上面获取到的边自然而然获取到对应src和tgt所对应的entities。
根据entities和relations获取有关chunks
如果是Local Search,Global那边的relation和entity就没有,反之亦然,但如果是Hybrid,则是将这两者对应的entities和relations进行融合。

简短理解就是获取到的entities包括了chunk_ids, 表明某个entity从哪些chunks里获取,进行汇集,然后和用户原始query进行cos_sim排序。
那同理,某个relation也包含了从哪个chunk所获取到的,然后使用原始query进行排序。
LLM回答
基于上述三者,包装成一个大的prompt来进行回复。其prompt如下:
1 | -----Entities(KG)----- |
至此我们大致捋清了其实现方式。
总结
在上面每部分已经总结出来的问题除外,我认为其实现还可以加入多跳查询来满足更复杂的链路关系,不过这里也就见仁见智了~















 对应提示词:
对应提示词: