介绍
书接上文,layoutLM微调FUNSD数据集介绍了layoutlm和layoutxlm如何做named entity recognition,以及多模态-CLIP和多模态-字幕生成介绍多模态是如何融合的,本文继续基于layoutLM系列,基于huggingface document_question_answering来进行debug是如何实现的。
更新:针对layoutxlm在docvqa_zh上的训练代码已经放到document-qa啦。
原始数据
在这之前,都是在介绍如何处理数据,也即如下代码:
1 |
|
1 | dataset['test'].select(range(1)).to_dict().keys() |
可以看到,默认dataset有如上几个字段,其中query有德语以及英语,后面updated_dataset做了过滤,只保留了为英语的、以及长度小于512的,最终保留字段如下:
1 | updated_dataset['test'] |
反而变简单了,所以咱们也不用再刻意关注dataset了。
其中一条数据如下:
1 | aaa = updated_dataset['test'].select(range(1)).to_dict() |

图像处理
看看人家,标注的bbox之类的就不要啦,咱要自己搞。。不过这可以理解它是怎么处理滴。
这部分对应Preprocessing document images,也即如下代码。
1 | image_processor = processor.image_processor |
从image_processor进去,最终到apply_tesseract,其代码如下所示:
1 |
|
咱来看下tesseract识别结果:
1 | from PIL import ImageDraw |
识别结果如下:

可以看到,tesseract拿到每个词的识别坐标。
注意:这里忽略了图片本身操作,比如resize、reshape等操作哦
相关的也有:
 |
 |
|---|---|
| 原始图片1 | OCR1 |
文本处理
这部分对应Preprocessing text data.
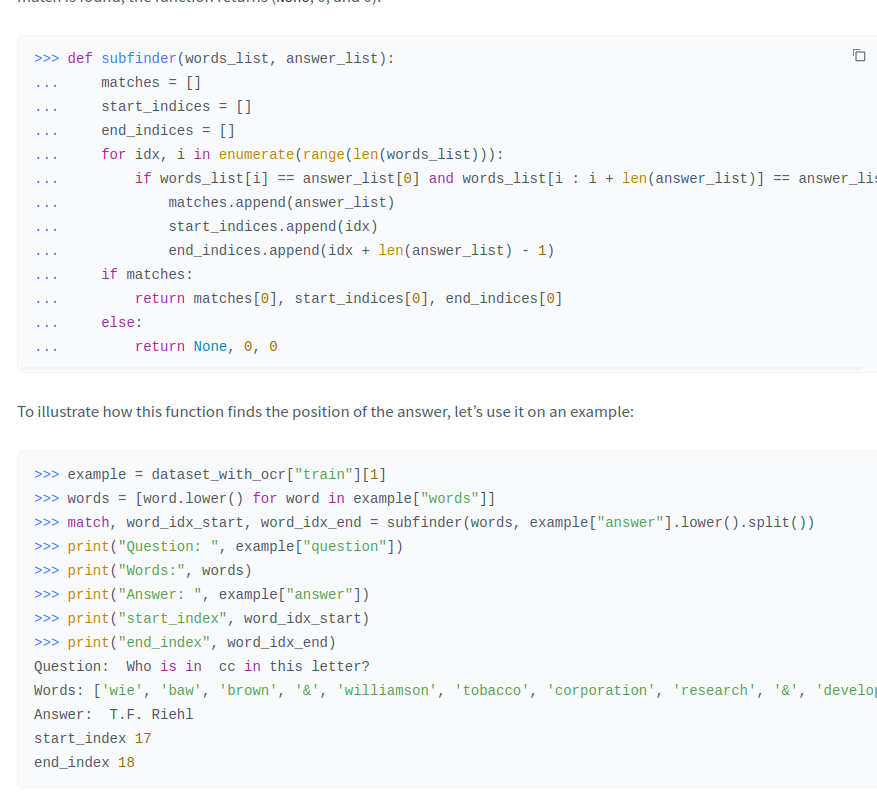
基于上图知道其answer为T.F. Riehl,通过subfinder函数其在原文的位置为start_index=17和end_index=18,通过OCR1图可知其具体位置。
接着tokenizer传入了question,words(ocr原文识别结果),boxes,我们来看其是怎么实现的以及其具体目的。
1 | encoding = tokenizer(example["question"], example["words"], example["boxes"]) |
在这之前,我们可以看到,其具体做的就是encode拿input_ids, attention_mask和token_type_ids,其具体如下:
1 |
|
但是也是从这开始,讲述了bbox是如何跟words对齐的。
其代码如下:
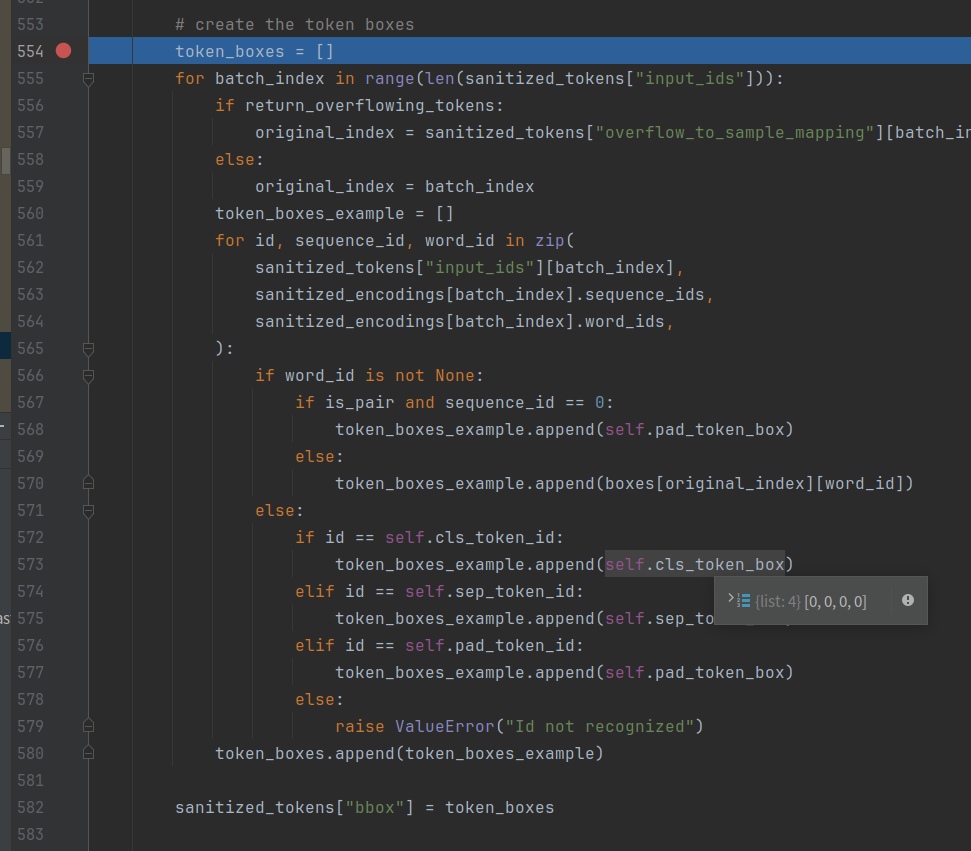
最终生成的结果如下:
1 |
|
着重看上图40~46行,即可明白tokenizer分成subword后,其box按照原词的box进行分配。这个也和原来使用layoutXLM来做是一样的,其在这里。
剩下部分就是encode_dataset函数了,除了和box对齐,另外一个就是基于subfinder函数来找到start_positions和end_positions来作为label。
至此,大致理解了其文本处理方式以及如何和box进行对齐,但是要注意subfinder函数,如果answer没有在words(即ocr识别原文)没有找到,这条数据就废掉了。
模型
模型部分简单如下:
1 | self |
但是一直没搞清楚其visual用的是resnet还是变种,不过这里就忽略了。。。(layoutLMv3用的就是ViT了)。
那接下来我们就一个目的了,看visual feature和text feature如何融合。
这部分反而看的云里雾里,比如为什么生成一个visual_bbox,剩下生成embedding、图像、transformer部分就是常规操作了,先忽略。
More
这种双指针的方式可以解决一部分文档问答问题,但是针对表格之类的,比如:
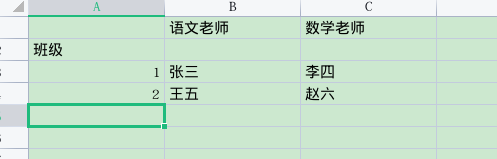
Q1: 班级1班的老师的姓名?
Q2: 班级1班语文老师的姓名和数学老师的姓名?
即一个表格中多个答案和一个疑问句中多个疑问点,就造成这类模型的是无法满足的。