


https://docs.conda.io/en/latest/miniconda.html
1 | chmod +x /code/packages/Miniconda3-latest-Linux-x86_64.sh && \ |
1 | /opt/conda/bin/python3.8 -m venv ~/venv |
http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1604/x86_64/
年终总结了,想了好久,一直想着应该总结些什么,但是总要开一个头。
相比南京,上海这里更多元(N维特征向量~),人来人往的人群,挤成狗而每天吵不完架的地铁,好吃的南京东路,标志性的打卡地方,惨淡的生活气息,努力的小伙伴,发挥着自己的才智和社交,这是我认识的北上广的生活。
这一年最重要的是遇到了自己喜欢的人,就像是突然抬起了头看了下天空,看,这更像是人生。
很遥远,但,就在那。
许巍的《故乡》中唱到,“你在我的心里永远是故乡”。
人生中还有比这更值得炫耀与努力的事情吗,貌似只有一个亿的小目标了~
如果不踏出这一步,人生一大遗憾。
踏出了,不知道。
但是不后悔。
我还年轻。
才28,算什么。
假设训练GPU不在自己机子上(悲伤脸),远程连接后,直接python train.py,但是如果一旦网络不稳定导致ssh断了,那这训练了一两天的心血可就白费了,所以需要一种简便的方式来后台运行,实现方式有多种,作为一个守护进程,比如supervisor或者systemctl那一些,但是对于算法人员来说这些都太复杂而不简单使用,所以此处推荐tmux。
使用步骤:
1 | $ tmux |
万事大吉,退出ssh后训练保持运行。
爬虫与反爬虫,是一个很不阳光的行业。
这里说的不阳光,有两个含义。
第一是,这个行业是隐藏在地下的,一般很少被曝光出来。很多公司对外都不会宣称自己有爬虫团队,甚至隐瞒自己有反爬虫团队的事实。这可能是出于公司战略角度来看的,与技术无关。
第二是,这个行业并不是一个很积极向上的行业。很多人在这个行业摸爬滚打了多年,积攒了大量的经验,但是悲哀的发现,这些经验很难兑换成闪光的简历。面试的时候,因为双方爬虫理念或者反爬虫理念不同,也很可能互不认可,影响自己的求职之路。本来程序员就有“文人相轻”的倾向,何况理念真的大不同。
然而这就是程序员的宿命。不管这个行业有多么的不阳光,依然无法阻挡大量的人进入这个行业,因为有公司的需求。
那么,公司到底有什么样的需求,导致了我们真的需要爬虫 / 反爬虫呢?
反爬虫很好理解,有了爬虫我们自然要反爬虫。对于程序员来说,哪怕仅仅是出于“我就是要证明我技术比你好”的目的,也会去做。对于公司来说,意义更加重大,最少,也能降低服务器负载,光凭这一点,反爬虫就有充足的生存价值。
那么爬虫呢?
最早的爬虫起源于搜索引擎。搜索引擎是善意的爬虫,可以检索你的一切信息,并提供给其他用户访问。为此他们还专门定义了 robots.txt 文件,作为君子协定,这是一个双赢的局面。
然而事情很快被一些人破坏了。爬虫很快就变的不再“君子”了。
后来有了“大数据”。无数的媒体鼓吹大数据是未来的趋势,吸引了一批又一批的炮灰去创办大数据公司。这些人手头根本没有大数据,他们的数据只要用一个 U 盘就可以装的下,怎么好意思叫大数据呢?这么点数据根本忽悠不了投资者。于是他们开始写爬虫,拼命地爬取各个公司的数据。很快他们的数据,就无法用一个 U 盘装下了。这个时候终于可以休息休息,然后出去吹嘘融资啦。
然而可悲的是,大容量 U 盘不断地在发布。他们总是在拼命地追赶存储增加的速度。
以上是爬虫与反爬虫的历史。
电子商务行业的爬虫与反爬虫更有趣一些,最初的爬虫需求来源于比价。
这是某些电商网站的核心业务。大家如果买商品的时候,是一个价格敏感型用户的话,很可能用过网上的比价功能 (真心很好用啊)。毫无悬念,他们会使用爬虫技术来爬取所有相关电商的价格。他们的爬虫还是比较温柔的,对大家的服务器不会造成太大的压力。
然而,这并不意味着大家喜欢被他爬取。毕竟这对其他电商是不利的。于是需要通过技术手段来做反爬虫。
按照技术人员的想法,对方用技术怼过来,我们就要用技术怼回去,不能怂啊。这个想法是很好的,但是实际应用起来根本不是这么回事。
诚然,技术是很重要的,但是实际操作上,更重要的是套路。谁的套路更深,谁就能玩弄对方于鼓掌之中。谁的套路不行,有再好的技术,也只能被耍的团团转。这个虽然有点伤技术人员的自尊,然而,我们也不是第一天被伤自尊了。大家应该早就习惯了吧。
大家应该听过一句话吧,大概意思是说,整个互联网上大概有 50% 以上的流量其实是爬虫。第一次听这句话的时候,我还不是很相信,我觉得这个说法实在是太夸张了。怎么可能爬虫比人还多呢? 爬虫毕竟只是个辅助而已。
现在做了这么久的反爬虫,我依然觉得这句话太夸张了。50%?你在逗我?就这么少的量?
举个例子,某公司,某个页面的接口,每分钟访问量是 1.2 万左右。这里面有多少是正常用户呢?
50%?60%?还是?
正确答案是:500 以下。
也就是说,一个单独的页面,12000 的访问量里,有 500 是正常用户,其余是爬虫。
注意,统计爬虫的时候,考虑到你不可能识别出所有的爬虫,因此,这 500 个用户里面,其实还隐藏着一些爬虫。那么爬虫率大概是:(12000-500)/12000=95.8%
这个数字你猜到了吗?
这么大的爬虫量,这么少的用户量,大家到底是在干什么? 是什么原因导致了明明是百人级别的生意,却需要万级别的爬虫来做辅助? 95% 以上,19 保 1?
答案可能会相当令人喷饭。这些爬虫大部分是由于决策失误导致的。
举个例子,这个世界存在 3 家公司,售卖相同的电商产品。三家公司的名字分别是 A,B,C。
这个时候,客户去 A 公司查询了下某商品的价格,看了下发现价格不好。于是他不打算买了。他对整个行业的订单贡献为 0。
然而 A 公司的后台会检测到,我们有个客户流失了,原因是他来查询了一个商品,这个商品我们的价格不好。没关系,我去爬爬别人试试。于是他分别爬取了 B 公司和 C 公司。
B 公司的后台检测到有人来查询价格,但是呢,最终没有下单。他会认为,嗯,我们流失了一个客户。怎么办呢?
我可以爬爬看,别人什么价格。于是他爬取了 A 和 C。
C 公司的后台检测到有人来查询价格。。。。。
过了一段时间,三家公司的服务器分别报警,访问量过高。三家公司的 CTO 也很纳闷,没有生成任何订单啊,怎么访问量这么高? 一定是其他两家禽兽写的爬虫没有限制好频率。妈的,老子要报仇。于是分别做反爬虫,不让对方抓自己的数据。然后进一步强化自己的爬虫团队抓别人的数据。一定要做到:宁叫我抓天下人,休叫天下人抓我。然后,做反爬虫的就要加班天天研究如何拦截爬虫。做爬虫的被拦截了,就要天天研究如何破解反爬虫策略。大家就这么把资源全都浪费在没用的地方了。直到大家合并了,才会心平气和的坐下来谈谈,都少抓点。
最近国内的公司有大量的合并,我猜这种“心平气和”应该不少吧?
下面我们谈谈,爬虫和反爬虫分别都是怎么做的。
首先是爬虫。爬虫教程你到处都可以搜的到,大部分是 python 写的。我曾经在一篇文章提到过:用 python 写的爬虫是最薄弱的,因为天生并不适合破解反爬虫逻辑,因为反爬虫都是用 javascript 来处理。然而慢慢的,我发现这个理解有点问题(当然我如果说我当时是出于工作需要而有意黑 python 你们信吗。。。)。
Python 的确不适合写反爬虫逻辑,但是 python 是一门胶水语言,他适合捆绑任何一种框架。而反爬虫策略经常会变化的翻天覆地,需要对代码进行大刀阔斧的重构,甚至重写。这种情况下,python 不失为一种合适的解决方案。
举个例子,你之前是用 selenium 爬取对方的站点,后来你发现自己被封了,而且封锁方式十分隐蔽,完全搞不清到底是如何封的,你会怎么办?你会跟踪 selenium 的源码来找到出错的地方吗?
你不会。你只会换个框架,用另一种方式来爬取。然后你就把两个框架都浅尝辄止地用了下,一个都没有深入研究过。因为没等你研究好,也许人家又换方式了。你不得不再找个框架来爬取。毕竟,老板等着明天早上开会要数据呢。老板一般都是早上八九点开会,所以你七点之前必须搞定。等你厌倦了,打算换个工作的时候,简历上又只能写“了解n个框架的使用”,仅此而已。
这就是爬虫工程师的宿命,爬虫工程师比外包还可怜。外包虽然不容易积累技术,但是好歹有正常上下班时间,爬虫工程师连这个权利都没有。
然而反爬虫工程师就不可怜了吗?也不是的。反爬虫有个天生的死穴,就是:误伤率。
我们首先谈谈,面对对方的爬虫,你的第一反应是什么?
如果限定时间的话,大部分人给我的答案都是:封杀对方的 IP。
然而,问题就出在,IP 不是每人一个的。大的公司有出口 IP,ISP 有的时候会劫持流量让你们走代理,有的人天生喜欢挂代理,有的人为了翻墙 24 小时挂 vpn,最坑的是,现在是移动互联网时代,你如果封了一个 IP?不好意思,这是中国联通的 4G 网络,5 分钟之前还是别人,5 分钟之后就换人了哦!
因此,封 IP 的误伤指数最高。并且,效果又是最差的。因为现在即使是最菜的新手,也知道用代理池了。你们可以去淘宝看下,几十万的代理价值多少钱。我们就不谈到处都有的免费代理了。
也有人说:我可以扫描对方端口,如果开放了代理端口,那就意味着是个代理,我就可以封杀了呀。
事实是残酷的。我曾经封杀过一个 IP,因为他开放了一个代理端口,而且是个很小众的代理端口。不出一天就有人来报事件,说我们一个分公司被拦截了。我一查 IP,还真是我封的 IP。我就很郁闷地问他们 IT,开这个端口干什么?他说做邮件服务器啊。我说为啥要用这么奇怪的端口?他说,这不是怕别人猜出来么?我就随便取了个。
扫描端口的进阶版,还有一种方式,就是去订单库查找这个 IP 是否下过订单,如果没有,那么就是安全的。如果有,那就不安全。有很多网站会使用这个方法。然而这其实只是一种自欺欺人的办法而已。只需要下一单,就可以永久洗白自己的 IP,天下还有比这更便宜的生意吗?
因此,封 IP,以及封 IP 的进阶版:扫描端口再封 IP,都是没用的。根本不要考虑从 IP 下手,因为对手会用大量的时间考虑如何躲避 IP 封锁,你干嘛和人家硬刚呢。这没有任何意义。
那么,下一步你会考虑到什么?
很多站点的工程师会考虑:既然没办法阻止对方,那我就让它变的不可读吧。我会用图片来渲染关键信息,比如价格。这样,人眼可见,机器识别不出来。
这个想法曾经是正确的,然而,坑爹的技术发展,带给我们一个坑爹的技术,叫机器学习。顺便带动了一个行业的迅猛发展,叫 OCR。很快,识别图像就不再是任何难题了。甚至连人眼都很难识别的验证码,有的 OCR 都能搞定,比我肉眼识别率都高。更何况,现在有了打码平台,用资本都可以搞定,都不需要技术。
那么,下一步你会考虑什么?
这个时候,后端工程师已经没有太多的办法可以搞了。 不过后端搞不定的事情,一般都推给前端啊,前端从来都是后端搞不定问题时的背锅侠。 多少年来我们都是这么过来的。前端工程师这个时候就要勇敢地站出来了:
“都不要得瑟了,来比比谁的前端知识牛逼,你牛逼我就让你爬。”
我不知道这篇文章的读者里有多少前端工程师,我只是想顺便提一下:你们以后将会是更加抢手的人才。
我们知道,一个数据要显示到前端,不仅仅是后端输出就完事了,前端要做大量的事情, 比如取到 json 之后,至少要用 template 转成 html 吧? 这已经是步骤最少最简单的了。然后你总要用 css 渲染下吧? 这也不是什么难事。
等等,你还记得自己第一次做这个事情的时候的经历吗?真的,不是什么难事吗?
有没有经历过,一个 html 标签拼错,或者没有闭合,导致页面错乱?一个 css 没弄好,导致整个页面都不知道飘到哪去了?
这些事情,你是不是很想让别人再经历一次?
这件事情充分说明了:让一个资深的前端工程师来把事情搞复杂一点,对方如果配备了资深前端工程师来破解,也需要耗费 3 倍以上的时间。毕竟是读别人的代码,别人写代码用了一分钟,你总是要读两分钟,然后骂一分钟吧?这已经算很少的了。如果对方没有配备前端工程师。。。那么经过一段时间,他们会成长为前端工程师。
之后,由于前端工程师的待遇比爬虫工程师稍好一些,他们很快会离职做前端,既缓解了前端人才缺口,又可以让对方缺人,重招。而他们一般是招后端做爬虫,这些人需要再接受一次折磨,再次成长为前端工程师。这不是很好的事情吗。
所以,如果你手下的爬虫工程师离职率很高,请仔细思考下,是不是自己的招聘方向有问题。
那么前端最坑爹的技术是什么呢?前端最坑爹的,也是最强大的,就是我们的:javascript。
Javascript 有大量的花样可以玩,毫不夸张的说,一周换一个 feature(bug) 给对方学习,一年不带重样的。这个时候你就相当于一个面试官,对方要通过你的面试才行。
举个例子,Array.prototype 里,有没有 map 啊?什么时候有啊?你说你是 xx 浏览器,那你这个应该是有还是应该没有啊?你说这个可以有啊?可是这个真没有啊。那 [] 能不能在 string 里面获取字符啊?哪个浏览器可以哪个不行啊?咦你为什么支持 webkit 前缀啊?等等,刚刚你还支持怎么现在不支持了啊?你声明的不对啊。
这些对于前端都是简单的知识,已经习以为常了。但是对于后端来说简直就是噩梦。
然而,前端人员自己作死,研究出了一个东西,叫:nodejs。基于 v8,秒杀所有的 js 运行。
不过 nodejs 实现了大量的 feature,都是浏览器不存在的。你随随便便访问一些东西(比如你为什么会支持 process.exit),都会把 node 坑的好惨好惨。而且。。。浏览器里的 js,你拉到后台用 nodejs 跑,你是不是想到了什么安全漏洞?这个是不是叫,代码与数据混合?如果他在 js 里跑点恶心的代码,浏览器不支持但是 node 支持怎么办?
还好,爬虫工程师还有 phantomjs。但是,你怎么没有定位啊? 哈哈,你终于模拟出了定位,但是不对啊,根据我当前设置的安全策略你现在不应该能定位啊?你是怎么定出来的?连 phantomjs 的作者自己都维护不下去了,你真的愿意继续用吗?
当然了,最终,所有的反爬虫策略都逃不脱被破解的命运。但是这需要时间,反爬虫需要做的就是频繁发布,拖垮对方。如果对方两天可以破解你的系统,你就一天一发布,那么你就是安全的。这个系统甚至可以改名叫做“每天一道反爬题,轻轻松松学前端”。
这又回到了我们开始提到的“误伤率”的问题了。我们知道,发布越频繁,出问题的概率越高。那么,如何在频繁发布的情况下,还能做到少出问题呢?
此外还有一个问题,我们写了大量的“不可读代码”给对方,的确能给对方造成大量的压力,但是,这些代码我们自己也要维护啊。如果有一天忽然说,没人爬我们了,你们把代码下线掉吧。这个时候写代码的人已经不在了,你们怎么知道如何下线这些代码呢?
这两个问题我暂时不能公布我们的做法,但是大家都是聪明人,应该都是有自己的方案的,软件行业之所以忙的不得了,无非就是在折腾两件事,一个是如何将代码拆分开,一个是如何将代码合并起来。关于误伤率,我只提一个小的 tip:你可以只开启反爬虫,但是不拦截,先放着,发统计信息给自己,相当于模拟演练。等统计的差不多了,发现真的开启了也不会有什么问题,那就开启拦截或者开启造假。
这里就引发了一个问题,往往一个公司的各个频道,爬取难度是不一样的。原因就是,误伤检测这种东西与业务相关,公司的基础部门很难做出通用的。只能各个部门自己做。甚至有的部门做了有的没做。因此引发了爬虫界一个奇葩的通用做法:如果 PC 页面爬不到, 就去 H5 试试。如果 H5 很麻烦,就去 PC 碰碰运气。
那么一旦有发现对方数据造假怎么办?
早期的时候,大家都是要抽查数据,通过数据来检测对方是否有造假。这个需要人工核对,成本非常高。可是那已经是洪荒时代的事情了。如果你们公司还在通过这种方式来检测,说明你们的技术还比较落伍。之前我们的竞争对手是这么干的:他们会抓取我们两次,一次是他们解密出来 key 之后,用正经方式来抓取,这次的结果定为 A。一次是不带 key,直接来抓,这次的结果定为 B。根据前文描述,我们可以知道,B 一定是错误的。那么如果 A 与 B 相等,说明自己中招了。这个时候会停掉爬虫,重新破解。
所以之前有一篇关于爬虫的文章,说如何破解我们的。一直有人要我回复下。我一直觉得没什么可以回复的。
第一,反爬虫被破解了是正常的。这个世界上有个万能的爬虫手段,叫“人肉爬虫”。假设我们就是有钱,在印度开个分公司,每天雇便宜的劳动力用鼠标直接来点,你能拿我怎么办? 第二,我们真正关心的是后续的这些套路。而我读了那篇文章,发现只是调用了 selenium 并且拿到了结果,就认为自己成功了。
我相信你读到这里,应该已经明白为什么我不愿意回复了。我们最重要的是工作,而不是谁打谁的脸。大家如果经常混技术社区就会发现,每天热衷于打别人脸的,一般技术都不是很好。
当然这并不代表我们技术天下第一什么的。我们每天面对大量的爬虫,还是遇到过很多高手的。就如同武侠小说里一样,高手一般都比较低调,他们默默地拿走数据,很难被发现,而且频率极低,不会影响我们的考评。你们应该明白,这是智商与情商兼具的高手了。
我们还碰到拉走我们 js,砍掉无用的部分直接解出 key,相当高效不拖泥带水的爬虫,一点废请求都没有(相比某些爬虫教程,总是教你多访问写没用的 url 免得被发现,真的不知道高到哪里去了。这样做除了会导致机器报警,导致对方加班封锁以外,对你自己没有任何好处)。
而我们能发现这一点仅仅是是因为他低调地写了一篇博客,通篇只介绍技术,没有提任何没用的东西。
这里我只是顺便发了点小牢骚,就是希望后续不要总是有人让我回应一些关于爬虫的文章。线下我认识很多爬虫工程师,水平真的很好,也真的很低调(不然你以为我是怎么知道如何对付爬虫的。。。),大家都是一起混的,不会产生“一定要互相打脸”的情绪。
早期我们和竞争对手打的时候,双方的技术都比较初级。后来慢慢的,爬虫在升级,反爬虫也在升级。这个我们称为“进化”。我们曾经给对方放过水,来试图拖慢他们的进化速度。然而,效果不是特别理想。爬虫是否进化,取决于爬虫工程师自己的 KPI,而不是反爬虫的进化速度。
后期打到白热化的时候,用的技术越来越匪夷所思。举个例子,很多人会提,做反爬虫会用到 canvas 指纹,并认为是最高境界。其实这个东西对于反爬虫来说也只是个辅助,canvas 指纹的含义是,因为不同硬件对 canvas 支持不同,因此你只要画一个很复杂的 canvas,那么得出的 image,总是存在像素级别的误差。考虑到爬虫代码都是统一的,就算起 selenium,也是 ghost 的,因此指纹一般都是一致的,因此绕过几率非常低。
但是!这个东西天生有两个缺陷。第一是,无法验证合法性。当然了,你可以用非对称加密来保证合法,但是这个并不靠谱。其次,canvas 的冲突概率非常高,远远不是作者宣称的那样,冲突率极低。也许在国外冲突是比较低,因为国外的语言比较多。但是国内公司通常是 IT 统一装机,无论是软件还是硬件都惊人的一致。我们测试 canvas 指纹的时候,在携程内部随便找了 20 多台机器,得出的指纹都完全一样,一丁点差别都没有。因此,有些“高级技巧”其实一点都不实用。
此外就是大家可能都考虑过的:爬虫违法吗?能起诉对方让对方不爬吗?法务给的答案到是很干脆,可以,前提是证据。遗憾的是,这个世界上大部分的爬虫爬取数据是不会公布到自己网站的,只是用于自己的数据分析。因此,即使有一些关于爬虫的官司做为先例,并且已经打完了,依然对我们没有任何帮助。反爬虫,在对方足够低调的情况下,注定还是个技术活。
到了后来,我们已经不再局限于打打技术了。反爬虫的代码里我们经常埋点小彩蛋给对方,比如写点注释给对方。双方通过互相交战,频繁发布,居然聊的挺 high 的。
比如问问对方,北京房价是不是很高啊? 对方回应,欧巴,我可是凭本事吃饭哦。继续问,摇到号了吗?诸如此类等等。这样的事情你来我往的,很容易动摇对方的军心,还是很有作用的。试想一下,如果你的爬虫工程师在大年三十还苦逼加班的时候,看到对方留言说自己拿到了 n 个月的年终奖,你觉得你的工程师,离辞职还远吗?
最后,我们终于搞出了大动作,觉得一定可以坑对方很久了。我们还特意去一家小火锅店吃了一顿,庆祝一下,准备明天上线。大家都知道,一般立 flag 的下场都比较惨的。两个小时的自助火锅,我们刚吃五分钟,就得到了我们投资竞争对手的消息。后面的一个多小时,团队气氛都很尴尬,谁也说不出什么话。我们组有个实习生,后来鼓足勇气问了我一个问题:“我还能留下来吗?”毕竟,大部分情况下,技术还是要屈服于资本的力量。
与竞争对手和解之后,我们去拜访对方,大家坐在了一起。之前网上自称妹子的,一个个都是五大三粗的汉子,这让我们相当绝望,在场唯一的一个妹子还是我们自己带过去的(就是上面提到的实习生),感觉套路了这么久,最终还是被对方套路了。
好在,吃的喝的都很好,大家玩的还是比较 high 的。后续就是和平年代啦,大家不打仗了,反爬虫的逻辑扔在那做个防御,然后就开放白名单允许对方爬取了。群里经常叫的就是:xxx 你怎么频率这么高,xxx 你为什么这个接口没给我开放,为什么我爬的东西不对我靠你是不是把我封了啊。诸如此类的。
和平年代的反爬虫比战争年代还难做。因为战争年代,误伤率只要不是太高,公司就可以接受。和平年代大家不能搞事情,误伤率稍稍多一点,就会有人叫:好好的不赚钱,瞎搞什么搞。此外,战争年代只要不拦截用户,就不算误伤。和平年代还要考虑白名单,拦截了合作伙伴也是误伤。因此各方面会更保守一些。不过,总体来说还是和平年代比较 happy。毕竟,谁会喜欢没事加班玩呢。
然而和平持续的不是很久,很快就有了新的竞争对手选择爬虫来与我们打。毕竟,这是一个利益驱使的世界。只要有大量的利润,资本家就会杀人放火,这不是我们这些技术人员可以决定的。我们希望天下无虫,但是我们又有什么权利呢。
好在,这样可以催生更多的职位,顺便提高大家的身价,也算是个好事情吧。
想来想去,不知道应该怎么写,离开了马鞍山,有点怀念了那里,可能是因为爱上一个人所以喜欢上一座城市吧。套用李志《关于郑州的记忆》中的歌词,
关于郑州我知道的不多
为了爱情也曾去过那里
每次和朋友聊起过去的旅行
一个人悄悄的想起她
不过没有那么伤感啦,马鞍山还是蛮小滴,整体市中心也没有很大,空气不错,比上海的天气要好得多,走在上海的街头,总能感觉到呼吸空气都能呼吸到颗粒的感觉,听说北京更可怕,啧啧啧,下面放图片。













Love you 马鞍山~,晚安。
MySQL 是一个分层设计架构,总提上可以分为 Server 层和存储层两层。如下图所示:
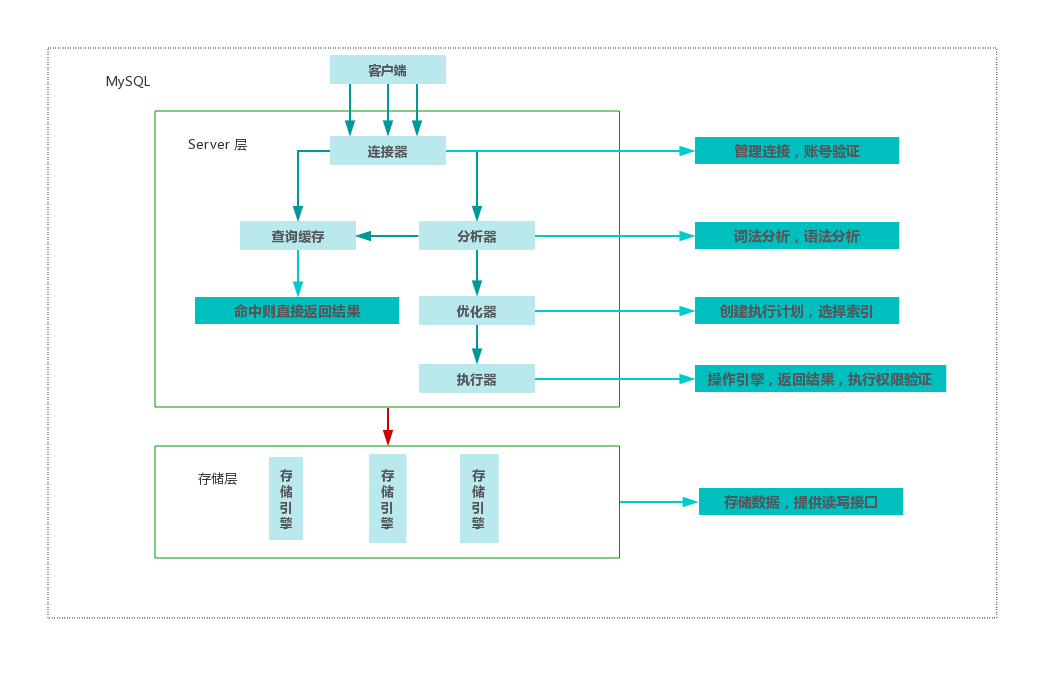
其中 Server 层又可以分为连接器,分析器,优化器,执行器四部分,涵盖 MySQL 大多数核心服务功能,以及所有的内置函数,所有跨引擎的功能都在这一层实现。各层负责的事情如下:
连接器:负责和客户端建立连接、获取权限、维持和管理连接,这个期间会负责校验用户身份,身份认证通过之后,连接器会查询到当前用户的所有的权限,后续的权限判断都会基于查询到的结果。可以通过 show processlist 查询到服务器已经建立的连接列表,如果连接建立完成之后,没有后续动作,那么这个连接的状态就处于 Sleep 状态。客户端如果太长时间没有任何操作,超过参数 wait_timeout 指定的时间之后,就会断开连接,再次操作需要重新连接。由于建立连接程序复杂,耗时较多,所以应该尽可能使用长连接,但长期使用长连接导致内存使用率增长很快,这是因为 MySQL 在执行过程中临时使用的内存都是管理在连接对象里面的,并且只有在连接断开的时候才会释放,长时间累计,可能导致 MySQL 被系统强行杀掉(OOM),所以我们应该在使用长连接的情况下,定期断开长连接,并且在执行大的操作之后,通过 mysql_reset_connection 来重新初始化连接资源,但不需要重新连和鉴权。此阶段常见的错误有:Access denied for user。
查询缓存:以 SELECT 语句为 key,将查询结果缓存,如果命中缓存,则直接返回给客户端。但是这个功能弊大于利,不建议使用,MySQL 8.0 已经废弃,因为缓存失效频繁,基本排不上用场。
分析器:真正开始执行语句之前,需要先对语句做词法分析和语法分析,识别出这个 SQL 语句要做什么操作,如果 SQL 语法错误,将会看到我们常见错误:You have an error in your SQL syntax。
优化器:经过分析器,优化器需要对 SQL 语句进行优化,优化器会在表里面有多个索引的时候,决定使用哪个索引,或者一个表有多表关联的时候,决定各个表的连接顺序,经过优化器处理,接下来就要到执行阶段了。
执行器:经过优化器的诊治之后,就到了真正执行的阶段了,但是在开始执行的时候,需要先判断对这个表有没有相应的操作权限,如果没有,就会返回没有权限的错误。
慢查询日志:slow_query_log包含执行时间超过 long_query_time 以及扫描行数超过 min_examined_row_limit 的 SQL 语句。慢查询日志用于去找到执行时间很长的 SQL 语句,可以使用 mysqldumpslow 用于分析慢查询日志
开启 MySQL 慢查询的方式如下(MySQL 5.7),修改配置文件 /etc/mysql/mysql.conf.d/mysqld.cnf,添加:
1 | [mysqld] |
Redo Log 详细介绍,详见。与查询流程不同的是,当要更新一条记录的时候,InnoDB 会先把记录写道 Redo Log,并且更新内存。这个时候就算是更新结束。同时,InnoDB 会在空闲的时候,将这个操作记录到更新到磁盘,这就是传说中的 WAL 技术。MySQL 中的 Redo Log 是固定大小的,比如可以配置为一组 4 个文件,每个文件大小是 4GB,具体由系统变量 innodb_log_file_size 和 innodb_log_files_in_group 控制。Redo Log 与 Bin log 不同的是,前者采用循环写的策略,而后者采用追加写。有了 Redo Log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的数据都不会丢失,这个能力称之为 Crash-Safe,详见。同时根据官方解释,Redo Log 是一个基于磁盘的数据结构(物理上存在与 MySQL 数据目录下,名称为:ib_logfile*),用于在奔溃恢复期间纠正不完整事务写入的数据。
有关 Biary Log 的官方文档,详见,配置参数详见。据官方文档介绍,Binary Log 包含描述数据库更新的事件,例如表创建或者更新,也包含了每个语句花在更新数据上的事件,主要目的有两个:
与 Redo Log 不同的时候,Redo Log 输入 InnoDB 引擎特有的日志,而 Binary Log 属于 MySQL Server 提供的日志。Redo Log 是物理日志,记录的是 “在某个数据页上做了什么操作”,而 Binary Log 记录的是逻辑日志,记录这个语句的原始逻辑。
对于下面这样的一条语句,它的详细执行过程是怎么样的?(InnoDB 引擎)
1 | update T set c=c+1 where ID=2; |
事务就是要保证一组数据库操作,要么全部成功,要么全部失败。MySQL 中,事务是由引擎层实现的,MySQL 是一个支持多引擎的系统,但是并不是所有的引擎都支持事务,这也是 MyISAM 被 InnoDB 取代的原因之一,事务具有四个性质:Atomicity、Consistency、Isolation、Durability。
当数据库中有多个事务的时候,就可能出现脏读,不可重复读,幻读的问题,为了解决这些问题,就有了隔离级别的概念。但是,在谈隔离级别的时候,要知道,隔离的越严实,效率就越低, SQL 标准事务中的隔离级别包括:读未提交,读提交,可重复读,串行化。
读未提交:一个事务还没提交时,它做的变更就能被别的事务看到;
读提交:一个事务提交之后,它做的变更才会被其他事务看到;
可重复读:一个事务执行过程中看到的数据,总是跟这个事务在启动的时候看到的数据是一致的。当然在此隔离级别下,未提交变更对其他的事务也是不可见的。
串行化:顾名思义,对于同一行记录,“写” 会加 “写锁”,“读” 会加 “读锁”,当出现锁冲突的时候,后访问的事务必须等待前一个事务执行完成,才能继续执行。
事务隔离级别的设置由参数 transaction_isolation 设定。
在 MySQL 中,实际上每一条更新语句在更新的时候都会同时记录一条回滚日志,记录上的最新值,通过回滚操作,就能得到前一个状态的值。假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会看到类似下面的记录:
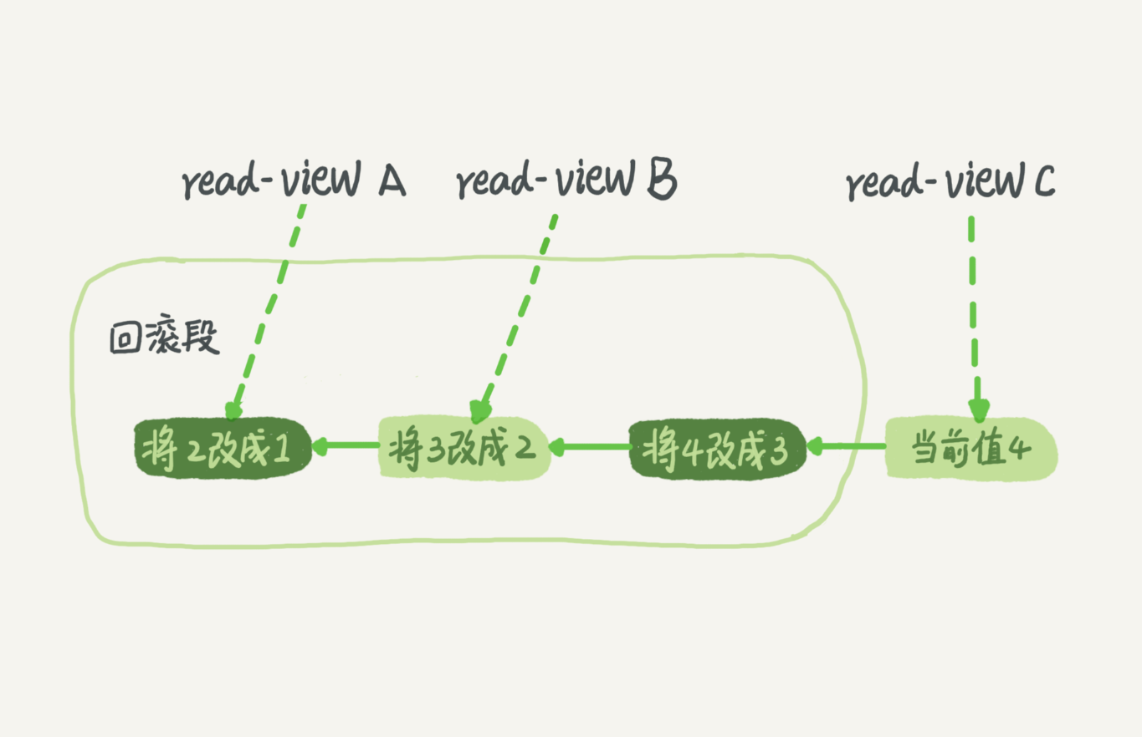
当前值是4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的 read-view,如图中,在不同事务 A、B、C里面,这一个记录的值分别是1、2、4,同一条记录可以在系统中存在多个版本,就是数据库的多版本并发控制(MVCC),就必须将当前值依次执行试图中所有的回滚操作得到。回滚日志会在不需要的时候删除,系统会判断,当再没有事务需要这些回滚日志的时候,回滚日志就会被删除。
MySQL 事务启动有以下两种:
commit work and chadin 用于提交本次事务,并且开启新的事务;
长事务意味着系统里面会存在很老的事务试图,由于这些事务可能访问数据库里面的任何数据,数据库里面用到的回滚日志都必须记录,导致占用大量存储空间。
使用如下 SQL 语句可以查询当前 MySQL 中执行时间超过 60s 的事务:
1 | select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60 |
数据库索引类似书籍目录,索引的出现就是为了加快查询的效率。常见的索引模型有:哈希表,有序数组和搜索树。
哈希表是一种 key-value 存储数据的结构,根据 key 计算出该 key 的具体存储位置,然后再读出,时间复杂度是 O(1),但是不支持范围查找并且可能存在冲突。
有序数组支持等值查询,也支持范围查找,但是在插入的时候,成本太大,最高时间复杂度 O(n),适用于静态数据,不存在插入的情况。
搜索树,二叉搜索数(BST)的查找,插入的是时间复杂度是O(logn),这里的n指的是树的高度,但是当数据量高达百万千万时,数据的高度会很大,在 MySQL 中,数据存储在磁盘中,增加了读磁盘的次数,就会增加响应时间,所以 MySQL 中索引数是 N 叉树,以 InnoDB 为例,这里的 N 大概差不多是 1200,所以在在树高3,4 层的时候,存储数据就将近20亿。
在 InnoDB 中,表都是根据主键顺序以索引的形式存在的,这种存储方式的表成为索引组织表,InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。InnoDB 的索引可以根据叶子节点存储的内容分为为主键索引和非主键索引,主键索引树叶子节点存储的是整行数据的内容,在 InnoDB 中,主键索引也称之为聚簇索引(clustered index),非主键索引的叶子节点内容是主键的值,在 InnoDB 中,非主键索引也被称为二级索引(secondary index)。所以在查询中,基于主键索引的查询和普通索引的查询是有区别的,基于主键索引的查询只需扫描主键索引这棵树,基于普通索引的查询需要先搜索普通索引树,然后再到主键索引树上查询,称为 回表。
自增主键是指在自增列上定义的主键,建表语句中我们一般会这么写:NOT NULL AUTO_INCREMENT PRIMARY KEY,那么在插入记录的时候,可以不指定这列的值,或者这列的值是 null 或者 0 的时候,系统会获取当前该列最大值加1作为下一条记录的值。自增主键的插入方式中,在维护主键索引树的时候,涉及到的基本都是追加操作,不会涉及到挪动索引树其他叶子节点,也不会触发叶子节点所在数据页的分裂,进而导致页合并删除等操作。
但是如果使用业务字段做主键,则往往不容易保证有序插入,这样写数据的成本较高。如果从存储的角度考虑,使用自增主键索引,可以降低对存储成本。例如,如果使用身份证号做主键,那么每个二级索引的主键占用约20个字节,而如果用整形做主键,则只要4个字节,即使长整形,也只要8字节而已。显然,主键长度越小,普通索引的叶子节点就越小,索通索引占用的空间也就越小。
不过在 KV 场景下,这种表中,只有一个索引,并且是唯一索引,那么我们就可以使用 key 字段作为主键了。
重建普通索引,可以使用如下的方式:
1 | alter table T drop index k; |
但是,重建主键索引的时候,万万不可如此:
1 | alter table T drop primary key; |
取而代之的是:alter table T engine=InnoDB,因为不管是创建主键还是删除主键,都会重建整张表。
对于如下的表:
1 |
|
当我们执行语句 select * from T where k between 3 and 5的时候,会首先去扫描普二级索引树 k,对于每一个匹配到的值,都要去主键索引树上查找整行数据记录的值。但是当我们执行 select ID from T where k between 3 and 5 的时候,因为索引树k中已经包含了 ID 值,索引不用回表。
由于使用覆盖索引可以减少树的搜索次数,显著提高查询性能,所以使用覆盖索引是一个常用的性能优化手段。因此,所谓覆盖索引,就是索引树中叶子节点的内容已经覆盖了我们查询数据的需求,不用再回到主键查找。
虽然索引可以起到加速查询的效果,但是如果我们为每一种查询情况都建立索引,那岂不是索引风暴了,在插入或者更新的时候,导致维护大量索引,也会影响效率。取而代之的是,我们建立多个字段的联合索引,利用 B+ 树索引前缀来定位记录。例如,我们用一个表里面的 name 和 age 字段建立联合索引:
1 | alter table t add index name_age_index ('nane', 'age'); |
这样我们在根据姓名查找(where name = "战三"),姓名和年龄组合查找(where name = "战三" and age=10),甚至查找姓张的人的时候,也能用到这个索引(where name like "张%"),可以看到,不只是索引的全部定义,只要满足最左前缀,就可以利用这个索引来加速检查。这个最左索引可是这个联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
基于前面的说明,在建立联合索引的时候,我们要考虑索引的复用能力,因为可以支持最左前缀,所以当已经有了 (a,b) 这个联合索引的时候,就不需要再在 (a) 上单独建立索引了,但是如果要单独查询b字段,就要在 b 上单独建立索引了。
MySQL 5.6 引入了 索引下推(ICP),对基于最左前缀匹配的查询做了查询优化。
全局锁,顾名思义就是对整个数据库实例加锁。MySQL 提供了一个添加全局读锁的方法,命令式 flush tables with read lock,当你想让整个库处于只读状态的时候,可以使用这个明令,之后其他线程以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(建表,修改表等)、更新类事务的提交语句。
全局锁的典型使用场景是,做全库逻辑备份,也即是把整个表都 select 出来存成文本。但是整库全局读很危险:
正确的全局备份是使用 MySQL 官方自带的工具:mysqldump,当 mysqldump 使用参数 –single-transaction 的时候,导数据之前会启动一个事务,来确保拿到一致性视图,由于 MVCC 的支持,这个过程是可以做数据更新的。这个功能是好,但前提是引擎要支持这个隔离级别,比如 MyISAM 这种不支持事务的引擎,如果备份过程中总有更新,那就破坏了备份的一致性,这时就不得不使用 FTWRL 命令了。
还有一种方式也可以将全库置于只读状态,那就是 set global readonly=true,但是这种不好,原因有二:
MySQL 里面表级锁有两种:一种是表锁,一种是云数据锁(meta data lock, MDL)。
表锁的语法是 lock tables … read/write,与 FTWRL 类似,可以用 unlock tables 主动释放锁,也可以在客户端断开的时候自动释放。需要注意,lock tables 除了限制别的线程读写外,也限定了本线程接下来的操作对象。
举个例子, 如果在某个线程 A 中执行 lock tables t1 read, t2 write; 这个语句,则其他线程写 t1、读写 t2 的语句都会被阻塞。同时,线程 A 在执行 unlock tables 之前,也只能执行读 t1、读写 t2 的操作。连写 t1 都不允许,自然也不能访问其他表。
另一类表级锁是 MDL(meta data lock),MDL 不需要显示使用,在访问一个表的时候会自动加上。MDL 的作用是保证读写的正确性,例如,当一个查询正在遍历一个表的时候,而执行期间另外一个线程对这个表结构做更改,删了一列,那么查询线程拿到的结果跟表结构肯定对不上,肯定是不行的。
MySQL 5.5 引入了 MDL,在对一个表做增删改查的时候,加 MDL 读锁,当要对表结构变更操作的时候,加 MDL 写锁。读锁之间不互斥,读写锁,写锁之间互斥,用来保证变更别结构操作的安全性。
既然如此,我们在对线上业务做表结构更改的时候,就要小心谨慎,否则,可能造成线上业务直接挂掉,那么如何安全地修改表结构呢?首先杀掉长事务,或者等事务执行完在 DDL,可以去 information_schema.innodb_trx 表中查找出长事务将其杀掉。但是如果是一个热点表,请求频繁,kill 事务可能就不管用了,刚杀完新的就起来了。这个时候,我们可以使用 MariaDB 提供的一个功能,在 alter table 语句里面指定等待时间,如果在这个等待时间里能拿到 MDL 写锁最好,如果拿不到也不要阻塞后面的业务语句:
1 | ALTER TABLE tbl_name NOWAIT add column ... |
MySQL 中的行锁是由各个引擎自己实现的,但是并不是所有的引擎都支持行锁,MyISAM就不支持行锁,不支持行锁意味着并发控制只能使用表级锁,对于这种引擎的表,同一张上任何时刻只能有一个更新在执行,这就会影响业务的并发度,InnoDB 引擎是支持行锁的。
InnoDB 事务中,行锁是需要的时候才加上的,但并不是不需要了就立刻释放,而是需要等到事务束时才释放,这就是 两阶段锁协议。由于行锁是在事务提交的时候才释放,所以合理的安排 SQL 顺序能够有效提高并发度,要把最可能造成冲突,最可能影响并发度的锁的申请时机尽量往后放.
当并发系统中不同线程出现循环资源依赖,涉及的线程都在等别的线程释放资源时,就会导致这几个线程都进入无限等待的状态,称为死锁。例如:
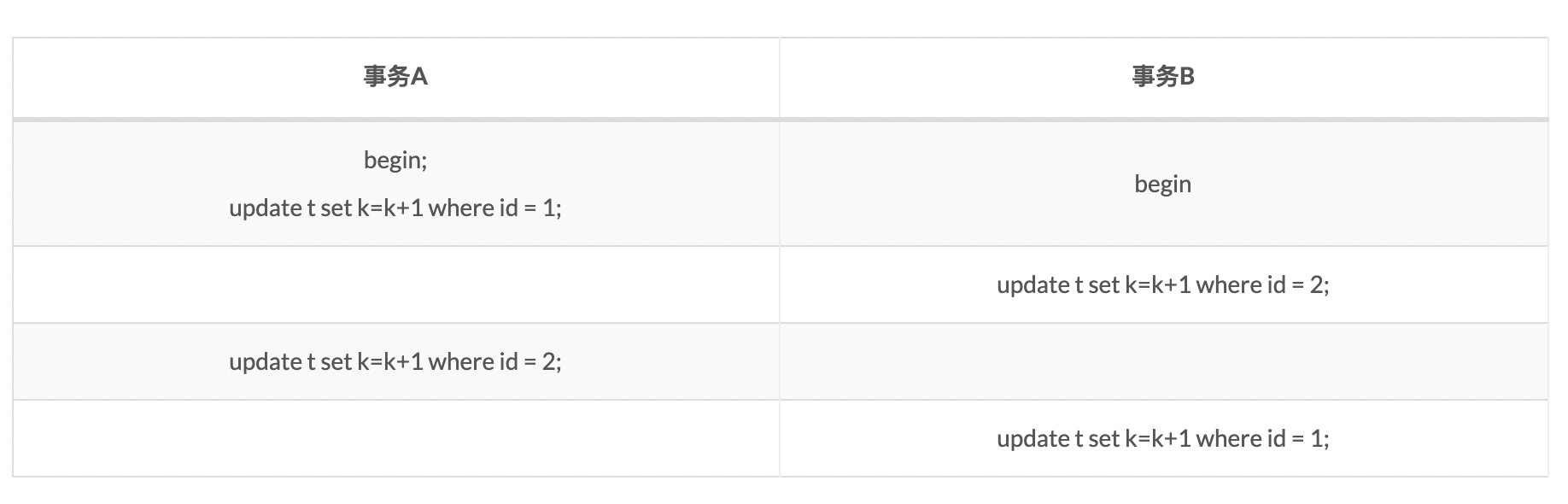
这个例子中,事务A在等待事务B释放id=2的行锁,事务B在等待事务A释放id=1的行锁,就进入了级锁状态。当出现死锁以后,有两种策略:
innodb_lock_wait_timeout 既不能太大也不能太小,大了客户端接收,默认时间 50s,哪个客户端能耐心能 50s,业务爸爸不早炸了。太小,又会误伤,简单的所等待也会被认为是死锁。
所以正常情况下,我们还是要采用第二种策略,主动死锁检测,而且 innodb_deadlock_detect 默认值本身就是 on,主动死锁加啊安策发生在死锁的时候,是能够快速发现并进行处理的。
--single-transaction 做逻辑备份的时候,如果主库的 binlog 传来一个 DDL 语句会如何?假设这个 DDL 是针对 t1,我们被把备份过程中几个关键语句列出来:
1 | Q1:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
备份开始的时候,为了确保 RR 隔离级别,再设置一次(Q1)。
启动事务,这里用 WITH CONSISTENT SNAPSHOT 确保拿到一致性视图(Q2)。
设置一个保存点(Q3);
show create table 是为了拿到表结构(Q4),然后正式导数据(Q5),回滚到 SAVEPOINT sp,在这里的所用释放 t1 的 MDL 读锁(Q6)。
根据 DDL 传过来的时刻,分为四种情况:
1 | mysql> CREATE TABLE `t` ( |
在这里强调一下,begin 和 start transaction 并不是一个事务的起点,在执行到他们之后的第一个操作 InnoDB 表的语句,事务才真正启动。如果要马上启动一个事务,可以使用 start transaction with consistent snapshot 命令。
可重复读隔离级别下,事务在启动的时候就拍了个快照,注意,这个快照是基于整库的。快照的实现不是拷贝数据,否则,要是数据库上百 GB,开启个事务早就废了。
要知道的是,InnoDB 引擎中每个事务有一个唯一的事务 ID,叫做 transaction_id,他是在事务开始的时候向 InnoDB 事务系统申请的,并且按申请顺序严格递增。
而且每行也都是有多个版本的,每次事务更新数据的时候,都会生成一个新的数据版本,并且把 transaction_id 赋值给这个版本的事务 ID,记为 row trx_id。同时,旧的数据版本要保留,并且在新的数据版本中,要有信息能够拿到它。
我们再来看 MySQL 是如何快速创建一致性视图的,按照可重复读的定义,一个事务启动的时候,能够看到所有已经提交的事务结果,但是之后,其他事务的更新对它不可见。因此,一个事务只需要在启动的时候声明说,“以我启动的时刻为准,如果一个数据版本是在我启动之前生成的,就认;如果是我启动以后才生成的,我就不认,我必须要找到它的上一个版本”。当然,如果“上一个版本”也不可见,那就得继续往前找。还有,如果是这个事务自己更新的数据,它自己还是要认的。
在实现上, InnoDB 为每个事务构造了一个数组,用来保存这个事务启动瞬间,当前正在“活跃”的所有事务 ID。“活跃”指的就是,启动了但还没提交。数组里面事务 ID 的最小值记为低水位,当前系统里面已经创建过的事务 ID 的最大值加 1 记为高水位。这个视图数组和高水位,就组成了当前事务的一致性视图(read-view)。而数据版本的可见性规则,就是基于数据的 row trx_id 和这个一致性视图的对比结果得到的。
这个视图数组把所有的 row trx_id 分成了几种不同的情况。
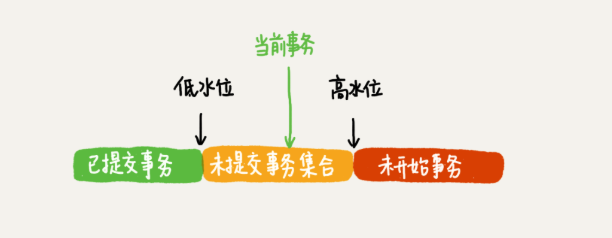
这样,对于当前事务的启动瞬间来说,一个数据版本的 row trx_id,有以下几种可能:
InnoDB 利用了“所有数据都有多个版本”的这个特性,实现了“秒级创建快照”的能力。一个数据版本,对于一个事务视图来说,除了自己的更新总是可见之外,有三种情况:
上面的规则仅仅是对于查询而言,但是对于更新,又是另一种情况了,请看下文,事务B的视图数组是先生成的,之后事务C才提交,不是应该看不见(1,2)吗,如何计算出(1,3)?
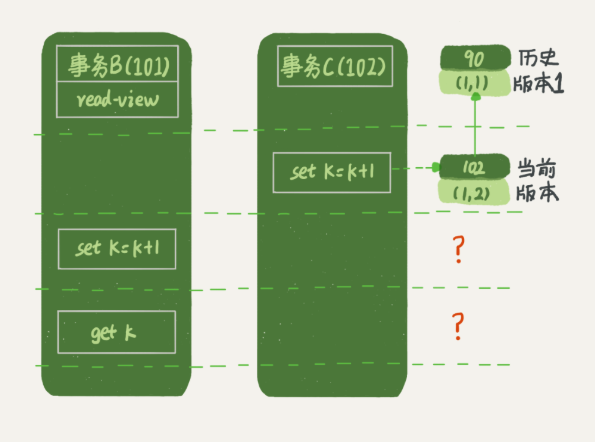
确实如此,如果这个事务更新之前查询一次数据,这个查询返回的k值确实是1,但是当要去更新数据的时候,就不能再在历史版本上更新了,否则事务C的更新就丢失了,因此,事务B此时的 set k=k+1 是在 (1,2)的基础上进行的操作。所以这里就用到了这样一条规则:更新数据时先读后写的,而这个读,只能读当前的值,成为 “当前读”(current read)。因此,在更新的时候,当前读拿到的数据时(1,2),更新后生成的数据是(1,3),这个新版本的 row trx_id 是101。所以,在执行事务 B 查询语句的时候,一看自己的版本号是 101,最新数据的版本号也是 101,是自己的更新,可以直接使用,所以查询得到的 k 的值是 3。这里我们提到了一个概念,叫作当前读。其实,除了 update 语句外,select 语句如果加锁,也是当前读。所以,如果把事务 A 的查询语句 select * from t where id=1 修改一下,加上 lock in share mode 或 for update,也都可以读到版本号是 101 的数据,返回的 k 的值是 3。下面这两个 select 语句,就是分别加了读锁(S 锁,共享锁)和写锁(X 锁,排他锁)。
1 | mysql> select k from t where id=1 lock in share mode; |
可重复读的核心就是一致性读(consistent read);而事务更新数据的时候,只能用当前读。如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待。
而读提交的逻辑和可重复读的逻辑类似,它们最主要的区别是:
那么,我们再看一下,在读提交隔离级别下,事务 A 和事务 B 的查询语句查到的 k,分别应该是多少呢?这里需要说明一下,“start transaction with consistent snapshot; ”的意思是从这个语句开始,创建一个持续整个事务的一致性快照。所以,在读提交隔离级别下,这个用法就没意义了,等效于普通的 start transaction。
下面是读提交时的状态图,可以看到这两个查询语句的创建视图数组的时机发生了变化,就是图中的 read view 框。
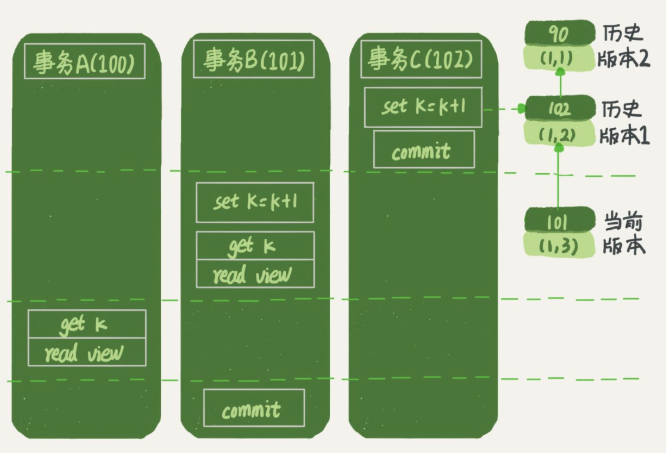
这时,事务 A 的查询语句的视图数组是在执行这个语句的时候创建的,时序上 (1,2)、(1,3) 的生成时间都在创建这个视图数组的时刻之前。但是,在这个时刻:
官方文档,当更新一个数据页的时候,如果数据页在内存中就直接更新,而如果这个数据没在内存中的话,在不影响数据一致性的前提下,InnoDB 会将这些更新操作缓存在 change buffer 中,这样就不需要从磁盘读入这个数据页了。在下次需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer 中与这个页有关的操作,通过这种方式就能保证这个数据逻辑的正确性。需要说明的是,虽然名字叫 change buffer,实际上他也是可以持久化的数据,也就是说,change buffer 在内存中有拷贝,也会被写入到磁盘上。
将 change buffer 中数据应用到原数据页,得到最新结果的过程称为 merge。除了访问这个数据页会触发merge外,后台线程也会定期merge,在数据库正常关闭的过程中,也会执行 merge 操作。
change buffer 使用的是 buffer pool 中的内存,因此不能无限增大,change buffer 的大小通过参数 innodb_change_buffer_max_size 来动态设置。
将数据从磁盘读入内存设计到随机IO,是数据库里成本最高的操作之一。change buffer 因为减少了随机磁盘访问,所以对性能的提升是很明显的。
但是并不是 change buffer 在任何场景下都能起到加速的作用,因为 merge 的时候是真正记性数据更新的时刻,而 change buffer 的主要目的是将记录的变更动作缓存下来,所以在一个数据页做 merge 之前,change buffer 记录的变更越多,收益就越大。因此,对于血多读少的业务来说,页面写完之后马上被访问到的概率很小,此时 change buffer 的使用效果最好。
和 redo log 降低随机写磁盘消耗不同的是,change buffer 降低了随机读磁盘的消耗。
就查询来说,影响可以忽略不计,例如对于查询语句:select id from T where k = 5,这个语句在索引树上查找的过程,先是通过 B+ 树从树根开始,按层搜索到叶子节点,然后可以再数据页内部通过二分法来定位记录:
我们知道,InnoDB 是按照数据页为单位来读写的,也就是说,当需要读取一条记录的时候,并不是将这个记录本身从磁盘读出来,而是以页为单位,将其整体读入内存,在 InnoDB 中,每个数据页的大小默认是 16kb。因此,说是找到某条记录,其实这条记录所在的数据页被读进内存,那么,对于普通索引来说,要多做的仅仅是 “查找和判断下一条记录是不是满足条件”,仅仅是指针移动一下而已。
对于更新过程来说,由于唯一索引的约束,要插入一条记录的时候,首先要判断是否存在那条记录,所以务必要将数据页读入内存判断。如果都已经读入内存了,那直接更新内存会更快,就没有必要使用 change buffer了。因此,唯一索引无法用到change buffer,实际上,只有普通索引才能用到。
因此如果要在一张表中插入一条新记录的时候,可以分为两种情况。
第一种情况,要更新的数据页在内存中,这种情况下,两者没有什么差别:
第二种情况,要更新的数据页不在内存中,处理如下:
对于这样一张表:
1 | mysql> create table SUser( |
我们可能由这样的查询场景:
1 | mysql> select f1, f2 from SUser where email='xxx'; |
MySQL 是支持前缀索引的,也就是说对于字符串字段,我们可以索引一部分,也可以索引整个字段,索引一部分,索引树占用字节更小,但同时会增加扫描次数,索引整个字段,可以做到精确查询,但是浪费了一点空间。有没有两全其美的方式呢,是有的,其实只要选择好前缀的长度,尽可能保证前缀区分度更大,既可以自做到节省空间,也可以做到减少查询次数。我们可以用类似下面的方式检查不同前缀长度的区分度:
1 | mysql> select |
还有一个因素要考虑的是,在需要返回这个前缀索引所在的字段时,使用前缀索引就无法使用覆盖索引优化了。对于字符串字段来说,我们还可以对这个字符串字段做一下处理再索引,例如:倒序,hash 之后再索引。
由于 InnoDB 采用 WAL 技术,为了减少随机写磁盘带来的开销,更新操作将会先写入 redo log,并且更新内存页,再在空闲的时间内存页中的内容写入磁盘,这个过程中内存页和磁盘数据不一致,这里的内存页就称为脏页,InnoDB 会在空闲的时间将脏页更新到磁盘,保证数据一致性。所以可能会发生这样的情况,平时执行很快的更新操作,其实就是在写内存和追加写日志,而有时候执行很慢,可能就是在刷脏页。
什么情况下引发 InnoDB 的刷脏页过程呢?
如何配置脏页刷新策略?
首先需要正确告知 InnoDB 所在主机的 IO 能力,这样才能让 InnoDB 知道需要全力刷脏页的时候可以刷多块。innodb_io_capacity 用来配置磁盘能力,这个值应该设置成磁盘的 IOPS。磁盘的 IOPS 可以通过工具 fio 来测试:
1 | fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M -numjobs=10 -runtime=10 -group_reporting -name=mytest |
InnoDB 决定是否要刷脏页,是根据两个因素:脏页比例,redo log 写盘速度计算出刷脏页的速度,innodb_max_dirty_pages_pct 用来设置脏页比例上限, innodb_flush_neighbors 用于设置如果脏页的相邻页即使脏页,要不要刷这个相邻的脏页。
自 MySQL 5.6.6 开始,innodb_file_per_table 默认为 ON,意思设置一个表的数据单独存储在一个文件中。由于 InnoDB 默认是按照页存储和读取数据的,当我们使用 delete 语句删除之后,实际上只是将相应数据页的相应位置记为可复用,并没有将空间回收,这样就会造成数据页存在空洞,插入数据也会造成这种情况。
处理这种情况的方法就是:alter table A engine=InnoDB ,这个命令在自 5.6 引入 Online DDL 之后,按照如下流程执行:
由于日志文件记录和重放操作这个功能的存在,这个方案在重建表的过程中,允许对表A做增删改操作,这也就是 Online DDL 名字的来源;
对于被很大的表来说,这个操作很消耗 IO 和 CPU 资源,因为涉及到大量的数据拷贝,因此,如果是线上服务,你要很小心控制操作时间,为了安全操作,推荐使用 Github 开源 gh-ost。
count(*) ?
不同于 MyISAM 引擎,InnoDB 没有吧一个表的行数存在磁盘上,所以对于 select count(8) from t 这样的操作来说,InnoDB 需要一行一行地从引擎中读出数据,然后计数。InnoDB 之所以不像 MyISAM 把这个数字保存在磁盘上,是由于 MVCC 的存在,InnoDB 也不知道现在数据表里面有多少条数据,如下图所示:

看上去傻傻的 MySQL 在执行 count(*) 的时候还是做了优化的,InnoDB 是索引组织表,主键索引树的叶子节点是数据,而普通索引树的叶子节点是主键值。所以,普通索引树比主键索引树小很多,对于 count(*) 这样的操作,遍历哪个索引树得到的结果逻辑上都是一样的。因此,MySQL 优化器会找到最小的那棵树来遍历。
虽然 show table status也能返回表的行数,但是这个只是个统计信息,不准确,这也是 MySQL 优化器有时会选错索引的原因之一。
count(pk_id),count(1),count(字段),count(*)?
count(*),例外,并不会把全部字段取出来,而是专门做了优化,不取值。count(*) 肯定不是 null,按行累加。所以结论是:按照效率排序的话,count(字段)<count(主键 id)<count(1)≈count(),所以我建议你,尽量使用 count()。
一个事务的 binlog 是有完整格式的:statement 格式的 binlog,最后会有 COMMIT;row 格式的 binlog,最后会有一个 XID event。
它们有一个共同的数据字段,叫 XID。崩溃恢复的时候,会按顺序扫描 redo log:
处于 prepare 阶段的 redo log 加上完整 binlog,重启就能恢复,由于 binlog 已经写入,没法回滚,如果拿着这个binlog恢复数据,就会导致数据不一致,所以在出库上也应该提交这个事务。
对于如下的事务:
1 | begin; |
这个事务要往两个表中插入记录,插入数据的过程中,生成的日志都得先保存起来,但又不能在还没 commit 的时候就直接写到 redo log 文件里。所以,redo log buffer 就是一块内存,用来先存 redo 日志的。也就是说,在执行第一个 insert 的时候,数据的内存被修改了,redo log buffer 也写入了日志。但是,真正把日志写到 redo log 文件(文件名是 ib_logfile+ 数字),是在执行 commit 语句的时候做的。
对于如下的表:
1 | CREATE TABLE `t` ( |
我们可能有这样的查询:
1 | select city,name,age from t where city='杭州' order by name limit 1000 ; |
我们在使用 explain 查看这个语句的查询计划时,可能会在 Extra 字段看到诸如 Using filesort 的字样,表示的就是这个 SQL 需要排序,MySQL 会给每个线程分配一段内存用于排序,称为 sort_buffer,大小由参数 sort_buffer_size 控制。
通常情况下,这个语句的执行过程如下,暂且成为全字段排序:
如果排序的数据量很小,sort_buffer 可以容纳,那就直接在内存中排序,否则就需要在临时文件中排序了,临时文件中排序采用的归并排序算法。
但是如果要返回的字段很多的话,sort_buffer 中存放的字段多太多,这样内存能够同时放下的行数很少,要分成多个临时文件,排序的性能会很差。MySQL 在单行长度超过 max_length_for_sort_data 时会采取另外一种算法,为了避免分割成多个临时文件,降低排序效率,这个算法的执行流程如下,暂且成为 rowid 排序:
之所要排序,是因为数据时无序的,那么可不可以利用索引树是有序存放这个原理,从而避免排序呢,答案是可以的?我们在这张表上建立一个 (city, name) 的联合索引,这样就不会在去排序,执行 explain,也不会看到需要排序的字样了:
1 | alter table t add index city_user(city, name); |
这个时候语句执行逻辑就如下这个样子了:
这个语句还需要字段 age,为了避免回表,我们可以创建这样一个联合索引:(city, name, age):
1 | alter table t add index city_user_age(city, name, age); |
这个时候,语句的执行流程就如下:
这个时候我们再去执行 explain,会看到 extra 字段有 Using index,表示使用了覆盖索引。
order by rand() 是如何执行的?
对于下面这样一个语句,MySQL 是如何执行的:
1 | mysql> select word from words order by rand() limit 3; |
由于 memory 引擎不是索引组织表,其中的位置信息可以想象成数组下表。在 InnoDB 中,一个表如果没有主键,InnoDB 会自己生成一个长度为 6 字节的 rowid 作为主键,实际上就是每个引擎用来为唯一标识每一行数据的信息。
总结,order by rand() 使用了内存临时表,内存临时表排序的时候使用了 rowid 排序方法。
但是临时表是由大小限制的,由参数 tmp_table_size 指定,默认 16MB,如果临时表大小超过了这个参数,那么内存临时表就会转成磁盘临时表,磁盘临时的使用默认引擎是 InnoDB ,这个由参数 internal_tmp_disk_storage_engine 指定,5.7.6 以后默认为 InnoDB。
order by rand() 这种写法会让计算过程非常复杂,需要扫描大量行数,因此排序过程中消耗的资源也很多,应该采取其他的方式实现。
对于如下的这张表:
1 | mysql> CREATE TABLE `tradelog` ( |
为何以下这两条语句用不到索引:
1 | mysql> select count(*) from tradelog where month(t_modified)=7; |
因为在对索引字段做了函数操作,就用不到索引了,需要走全标扫描,第一个语句很明显用了 month 函数,第二个语句有个潜在的转换,实际上相当于:
1 | mysql> select * from tradelog where CAST(tradid AS signed int) = 110717; |
第三个一个隐士的字符编码转换:
1 | select d.* from tradelog l, trade_detail d where CONVERT(traideid USING utf8mb4)=l.tradeid and l.id=2; |
所以总结为,对索引字段做函数操作,会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能,进而进行全表扫描。
首先当 SQL 语句执行很慢的时候,我们可以通过 show processlist 命令查看当前线程处于何种状态,主要有以下几个原因:
Waiting for table metadata lock,增删改查需要获取 MDL 读锁,如果此刻正在由某个线程更改表结构而没有释放表的 MDL 写锁,那么就需要等待;Waiting for table flush,这个状态表示一个线程正要对表 t 做 flush 操作,MySQL 中对表做 flush 操作的用法,一般有以下两个:1 | flush tables t with read lock; |
通常情况下,这两个语句执行很快,所以出现这种状态的原因是,有一个 flush table命令被别的语句堵住了,然后它由堵住了我们的语句。

幻读是在可重复读隔离级别下发生的,指的是一个事务在前后两次查询同一个范围的时候,后一次查询看到了前一次查询没有看到的结果。为了解决幻读,InnoDB 引入了间隙锁,也就是说,不仅可以给行加锁,行与行之间的间隙也是可以加锁的,但是间隙锁不同于行锁,与间隙锁冲突的是往这个间隙插入一条记录这个操作,间隙锁之间不存在冲突关系。间隙锁和行锁合称为 next-key lock,每个 next-key lock 是前开后闭区间。不过间隙锁的引入,虽然解决了幻读问题,但同时锁住了更大的范围,进而影响并发度。
如果是在读提交隔离级别下,是没有间隙锁的,但同时为了解决可能出现的数据和日志不一致问题,需要把 binlog_format 格式设置成 row。
锁规则里面,包含了两个“原则”、两个“优化”和一个“bug”:
面对短连接风暴,如果系统提示错误,Too many connectyions 就是说当前 Server 的连接数超过了 max_connections 的限制,紧急情况下可以调高此值的限制,但是虽然客户端可以连接成功,但是由于 CPU 资源有限,线程的请求无法得到执行,或者干掉那些长时间空闲的连接。
如果是查询慢,可以通过紧急添加索引的方式或者 query rewrite 的方式缓解。
更改表结构的时候,可以设定获取 MDL 写锁的时间,避免因更改表结构而影响线上业务正常执行;
innodb_flush_log_at_trx_commit=1 事务提交时,持久化 Redo Log 到磁盘;sync_binlog=1 每次事务的 binlog 也都持久化到磁盘;autocommit=1 开启自动事务提交,需要事务的时候,手动开启。字符串一次替换,为什么不能多次替换呢,例如
1 | s = """ |
假设150要被替换成170,而170要被替换成190,如果for循环的话,
1 |
|
就会导致结果出现偏差,整个字符串都会变成190,那么应该有种方法,可以一次性的匹配完并且返回结果。
关于re.sub.
1 | from typing import Dict |
实际会被匹配到,但是替换值时会触发KeyError,所以返回group(0)
1 | formula_1 = """ |
由于150会被160替换,所以只有此处不会触发KeyError
1 | formula_2 = """ |
150会被160替换,170会被180替换,由于sub只走一次,而rep函数会被循环匹配
1 |
|
同理如上
1 |
|
sub可以传函数是一个非常有用的做法,其中rep函数会在sub匹配到多次调用,然后最终sub一次返回,这个非常有用。
1 |
|
示例图:

前几日操作truncate table操作时,遇到一个问题,通过show processlist获取关键信息,通过此文章了解更多,故记录于此。

在MySQL以前的版本中,存在这样一个Bug:

大致意思如下:
如果user1存在一个操作table的事务,而user2要删除这张表,当user1提交这个事务时,binlog表现出来的行为类似如下:
1 | DROP TABLE t; |
这样就导致这个问题出现了。
所以MySQL在后续版本中增加了Metadata Lock,只有在事务结束后才会释放Metadata lock,因此在事务提交或回滚前,是无法进行DDL(不仅仅是DDL哦)操作的。
MySQL官方文档地址:
http://dev.mysql.com/doc/refman/5.6/en/metadata-locking.html

查询当前正在运行的事务(下面为拷贝过来的,仅作参考)
1 | mysql> select * from information_schema.innodb_trx\G |
查看运行的SQL语句
根据查询到的trx_started时间以及trx_mysql_thread_id到MySQL的general log中查找,当然前提是开启了general log的功能,对于这句话我有一个疑惑点,如果没有开启general log时那么无法查看对应操作的SQL语句了???
所以此处给出排查方式:
1 | -- 这条语句用于查看哪个线程被另外哪一个线程阻塞, 分别为 阻塞的线程ID、阻塞的SQL的语句、谁阻塞的、阻塞者的SQL语句 |
但是方式2不一定能够打印出具体阻塞的语句,为什么,如果出现此类问题,可以先看下autocommit,哈哈…
如果还是无法定位SQL,那么还是暴力一点:
1 | mysql> kill 52402; |
如何复现这种情况(另外对于主主/主从复制也会出现),可参考文章
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true