这个方式来自HanLP,具体就不细讲了,大家看代码即可。
1、如果后续处理需要[CLS]和[SEP]
1 |
|
2、后续不需要[CLS]和[SEP]
1 | # -*- coding: utf8 -*- |
这个方式来自HanLP,具体就不细讲了,大家看代码即可。
1 |
|
1 | # -*- coding: utf8 -*- |
第二篇文章,通过一种新的方式来实现以首字表示词向量
也可以看这里:一些mask的操作理解 gather部分。
1 |
|
1 |
|
output:
1 | tensor([[[ 101, 0, 0], |
1 |
|
到此,能够拿到以词为级别的output,embed.shape查看一下即可,后续就可以concat其他input做多输入。
这里以BertForMaskedLM为例,记录下BertModel的网络结构和一些思考,cls那部分网络结构不涉及,即BertOnlyMLMHead那部分。
1 | BertForMaskedLM( |
transformer里面的positional embedding,是正余弦绝对位置编码,对于sequence分配不同的position id。而bert是学习出来的,分配一个(512,768)embedding。
随后word_embedding,positional embedding, token_type_embedding进行相加,然后经过LN、dropout获得最终embedding。
在transformer结构里,是没有这个中间层的,细看下,是将768扩大4倍,随后在BertOutput那里又降维到768。那bert加这一个linear的作用是干嘛的呢?
搜了下网上的看法,很少关注或者没有相关思考。但是这这篇论文:Undivided Attention: Are Intermediate Layers Necessary for BERT? 给出了自己的解释。作者观点如下:
1 | In recent times, BERT-based models have been extremely successful in solving a variety of natural language processing (NLP) tasks such as reading comprehension, natural language inference, sentiment analysis, etc. All BERT-based architectures have a self-attention block followed by a block of intermediate layers as the basic building component. However, a strong justification for the inclusion of these intermediate layers remains missing in the literature. In this work we investigate the importance of intermediate layers on the overall network performance of downstream tasks. We show that reducing the number of intermediate layers and modifying the architecture for BERT-Base results in minimal loss in fine-tuning accuracy for downstream tasks while decreasing the number of parameters and training time of the model. Additionally, we use the central kernel alignment (CKA) similarity metric and probing classifiers to demonstrate that removing intermediate layers has little impact on the learned self-attention representations. |
结论就是实验后发现降低网络复杂度后,同时也能保持微调任务的准确性。
之前在看mask language model时,如何做数据处理那里一直没有太本质理解,比如15%做mask,然后又80%做mask,10%不变,10%随机选择,所以这里将mlm数据处理部分的代码列出来,方便需要者可以看到bert是怎么实现的。
另外关于mlm分词wordpience还是整词甚者ngram,这里不做探讨,本质来讲就是数据处理的方式不同,其他对于训练和上游使用预训练模型来讲并不影响。
1 | import collections |

从测试代码可以看到:
10,以embedding出来为准,输出维度为: (32, 3, 30)
rnn第一步初始化hx(10, 32, 4),一共初始化了num_layer=10层,batch_size=32,hidden_size=4,白话文就是每一层rnn都有一个(32, 4)的矩阵来保存最后一个时刻(ht)的结果。
这个可以看class RNNBase(Module):。
另外还有2个weight,2个bias的初始化。即公式中的w和b
初始化参数后,调用此方法,进行rnn计算,如果支持GPU,就会使用cudnn提供好的,此处忽略这里。
1 | def AutogradRNN(mode, input_size, hidden_size, num_layers=1, batch_first=False, |
1 |
|
1 | def Recurrent(inner, reverse=False): |
1 | # 针对rnn |
1 | # -*- coding: utf8 -*- |
至此,前向过程完结。
条件随机场是一种给定输入随机变量x,求解条件概率p(y|x)的概率无向图模型。用于序列标注任务时,会特例化为线性链条件随机场。此时输入和输出序列为等长。
对于序列标注任务,此类任务有分词、词性标注等,本质是对每一个字(假设bert做特征提取)进行预测,然后接全连接层进行softmax激活,如下图所示:
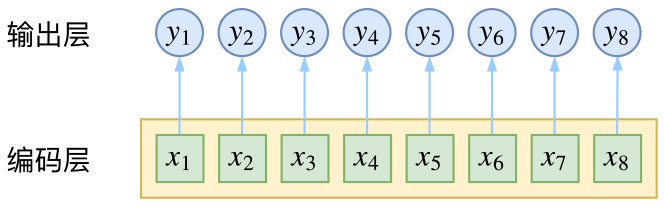
以词性标注任务来讲,x表示观测序列,y表示预测序列,即词性分布。
按照中文使用规律来讲,动词后面接动词的可能性基本不存在(或者对于分词任务来讲蝴后面基本就是蝶),而在上述模型中,观测序列没有考虑彼此之间的关联。
对于一个长度为n的句子,一共有m个词性,那么一共有m * n个可能性。
crf引入了预测序列的关联,并以路径为单元,预测m^n个可能性中求最优的路径。
在计算下面条件概率时,引入了以下几个假设进行简化计算:
1 | P(y1,…,yn|x1,…,xn)=P(y1,…,yn|x),x=(x1,…,xn) |
对其进行-log,变成相加问题,求其最大似然估计。

其中:
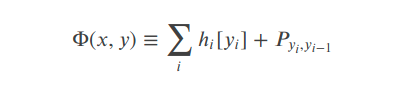
这个函数前一部分表示rnn到输出(标签)的发射概率矩阵,后一部分表示相邻标签的状态转移概率矩阵。
第一部分获取上述公式的计算结果,即分子项的计算结果,为目标的序列的打分结果。计算函数
第二部分是要求解分母项,需要在所有可能的路径上进行打分进行指数求和。计算函数
因为只考虑临近项,那么就可以递归的求出归一化因子,使用动态规划的方式获取所有路径的得分指数和。
在计算好的状态转移矩阵和发射概率矩阵,使用viterbi算法获取序列的最优路径解。
viterbi算法不是为nlp所生的,求解最优路径也有其他的算法,比如dijkstra,prim等。但是本质区别在于viterbi是动态规划算法,后两者属于贪心算法,计算资源消耗更多。另外动态规划本质是空间换时间。
关于viterbi动态规划求解,求解步骤如下:
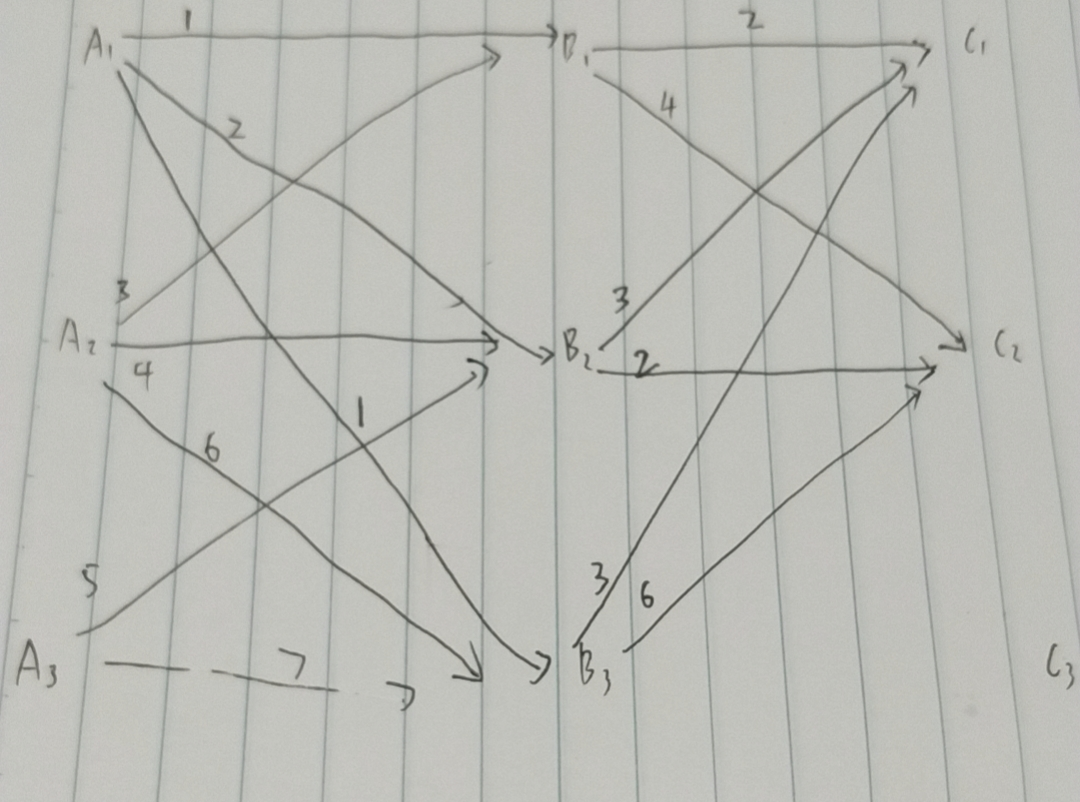
从最左边开始,
A1,A2,A3都是起点,A1 -> B1为1, A2 -> B1为3,A3 -> B1(我擦,漏了。。假设为4),那么A1,A2,A3到B1的最短路径为1(即A1 -> B1)。
同理得到B2的最短路径为2(即A1->B2),到B3的最短路径为1(A1->B3)。
从B1,B2,B3到C1的最短路径为2(即B1 -> C1),到C2的最短路径为2,(B2 -> C2),后续忽略。那么得到下张图:
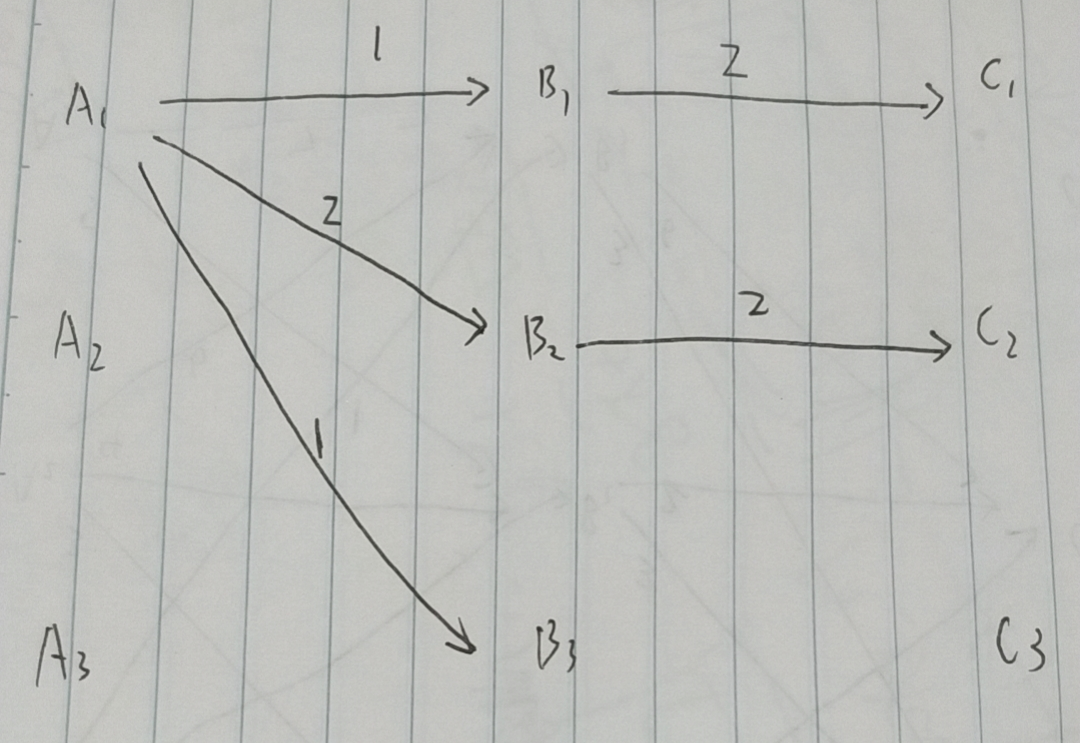
可以看出,到C1最短路径为(A1 -> B1 -> C1),到C2最短路径为(A1 -> B2 -> C2)。
至此,求解过程完毕。
“……一个随机过程,在这个过程中,鉴于现在,未来独立于过去。”
假设一个带有公平硬币的简化抛硬币游戏。暂停怀疑并假设马尔可夫性质尚不清楚,我们想预测 10 次翻转后翻转正面的概率。在条件依赖的假设下(硬币具有过去状态的记忆,未来状态取决于过去状态的顺序),我们必须记录导致第 11 次翻转的特定顺序以及这些翻转的联合概率。所以想象在 10 次翻转后,我们有一个随机的正面和反面序列。该序列的联合概率为 0.5^10 = 0.0009765625。在条件依赖下,下一次翻转的概率为 0.0009765625 * 0.5 = 0.00048828125。
这是第 11 次翻转的真实概率吗?一定不行!
我们知道,抛硬币的事件并不取决于之前抛硬币的结果。硬币没有记忆。连续翻转的过程不会对先前的结果进行编码。每次翻转都是一个独特的事件,正面或反面的概率相等,也就是有条件地独立于过去的状态。这就是马尔可夫性质。
马尔可夫链(模型)描述了一个随机过程,其中未来状态的假设概率仅取决于当前过程状态,而不取决于它之前的任何状态(shocker)。
让我们进入一个简单的例子。假设您想对给定当前状态的狗处于三种状态之一的未来概率进行建模。为此,我们需要指定状态空间、初始概率和转移概率。
想象一下你有一只非常懒惰的胖狗,所以我们将状态空间定义为睡觉、吃饭或大便。我们将初始概率分别设置为 35%、35% 和 30%。
1 | import numpy as np |
下一步是定义转移概率。它们只是在给定当前状态的情况下保持相同状态或移动到不同状态的概率。
1 | q_df = pd.DataFrame(columns=states, index=states) |

现在我们已经设置了初始和转移概率,我们可以使用Networkx 包创建一个马尔可夫图。
要做到这一点,需要一点灵活的思维。Networkx 创建 由节点和边组成的图。在我们的玩具示例中,狗的可能状态是节点,边是连接节点的线。转移概率是权重。它们表示在给定当前状态的情况下转换到某个状态的概率。
需要注意的是 networkx 主要处理字典对象。话虽如此,我们需要创建一个字典对象来保存我们的边及其权重。

不错。如果你沿着任何节点的边走,它会告诉你狗转换到另一个状态的概率。例如,如果狗在睡觉,我们可以看到狗有 40% 的机会继续睡觉,40% 的机会狗醒来并拉屎,20% 的机会狗醒来吃东西。
考虑这样一种情况,您的狗行为异常,并且您想对狗的行为是由于疾病或其他方面健康时的古怪行为进行建模的可能性。
在这种情况下,狗的真实状态是未知的,因此 对您隐藏。对此进行建模的一种方法是假设 狗具有 代表真实隐藏状态的可观察行为。让我们来看一个例子。
首先,我们创建我们的状态空间——健康或生病。我们假设它们是等概率的。
1 |
|

这是它变得更有趣的地方。现在我们创建发射或观测 概率矩阵。该矩阵的大小为 M x O,其中 M 是隐藏状态的数量,O 是可能的可观察状态的数量。
给定当前的可观察状态,发射矩阵告诉我们狗处于隐藏状态之一的概率。
让我们保持与上一个示例相同的可观察状态。狗可以睡觉、吃东西或大便。现在我们做出最好的猜测来填充概率。

看这个图时,将healthy和sick作为同一level,从sleeping,pooping, eating到healthy和sick的边就是发射概率。
隐马尔可夫图稍微复杂一些,但原理是相同的。例如,您会预期,如果您的狗正在进食,那么它健康的可能性很高 (60%),而生病的可能性非常低 (10%)。
现在,如果您需要根据一系列观察结果随着时间的推移辨别您的狗的健康状况怎么办?
使用Viterbi 算法,我们可以根据观察序列确定最可能的隐藏状态序列。
高的水平,在每个时间步长Viterbi算法的增量,寻找最大 的是得到陈述的任何路径的概率我在时间牛逼,那也 有序列最多时间正确的观察牛逼。
该算法还跟踪每个阶段概率最高的状态。在序列的末尾,算法将向后迭代,选择每个时间步“获胜”的状态,从而创建最可能的路径,或可能导致观察序列的隐藏状态序列。
最终代码:
1 |
|
结果:
1 |
|
相关代码: https://github.com/geasyheart/algo/commit/6cf0beca368d6c94f4a19c87f43b31e63306e0a3
下派一个任务,研究下推荐系统,貌似后面和电信搞一个类似电视视频内容推荐之类的项目.
这个推荐比较简单些,就是根据视频的得分来进行排序,排除掉当前用户已经看过的,剩下的再排序返回给用户就行.
好处是这是一个非常简单但是非常有效的算法,基本来说我们看视频都是根据播放量高、得分高进行播放。
坏处是有一个长尾效应,过于小众的基本不会推荐出来,看看京东,其实也有点类似这样~
关于视频的打分,这个可以根据一些特征工程来获得,比如用户点赞,收藏,喜欢,浏览,基于不同权重进行得分。
如果没有这些特征,可以手动构造这些视频的得分(不行可以抓豆瓣。。。)甚者直接根据用户的浏览记录进行排序就能上线。
对于长尾效应,可以运营分出几大类,根据类别再进行排序也是可以一定程度多了新的选择。
对于冷启动,这个咋说呢,一开始肯定都是没有数据的,可以先按照热度排个序上了线后续优化。
这是一个基于内容特征进行推荐的方式。
比如说,张三看过言情、虐心电影A,那如果电影B也具有这种feature,就可以计算这些feature的相似度进行排序推荐给A。
至于特征有多少,emmm,可以打标签,比如导演,演员,简介tfidf,小清新,狗血之类。
另外如果基于深度学习的话,就要获得视频的向量,根据向量来进行排序推荐给A。
协同过滤推荐重点在于协同。这里可以分成两类:
啥意思呢,用户张三喜欢看A,B,D电视剧,用户李四喜欢看A,D,那么张三和李四是挺相似的,那么就可以推荐给李四用户B电视剧。这个就叫基于用户的协同过滤。
至于特征,也可以说张三和李四有其他特征,比如都是男的,年龄相仿,兴趣相仿,那就可以认为是同一类人,那推荐的内容也是可以类似的。
基于内容的呢,其实和上面的基于内容的推荐是挺类似的。
核心点是基于历史的数据进行来预测用户的相似程度来进行推荐内容,将人和人也关联到一起。
一种做法通过SVD(奇异值分解)来实现。
比如下面例子:
1 | # -*- coding: utf8 -*- |
啦啦啦,现在也可以尝试其他做法,比如wide&deep,DSSM,DeepFM,pairwise,pointwise,具体看业务。
以后再有机会更新。
前段时间面试了一个大佬,他之前在腾讯做过腾讯新闻个性化推荐,在2016~2019年期间,他的做法是这样的,
一共有三个graph,user,tag,article,将这三个进行关联到一起形成user-tag-article网络,基于这个网络进行随机游走,然后使用word2vec进行向量化,进行推荐。
虽然这种技术可能放到现在来说有点落伍了,但是对这种做法挺感兴趣,整体实现思路也并不难,所以尝试了下。
我将代码放到了graph word2vec embedding,感兴趣的话可以看看~
之前线上代码更新的时候报了一个migration类似的错误,报错信息如下:
1 | django.db.utils.OperationalError: (1054, "Unknown column 'age' in 'field list'") |
出现错误的代码模型文件为:
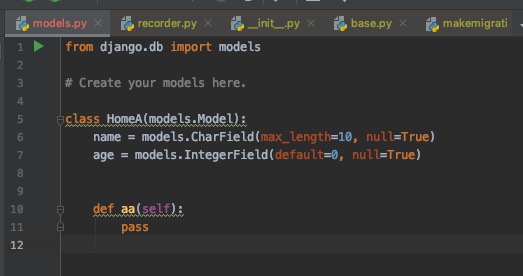
出现错误的代码对应的migration/001.py文件为:
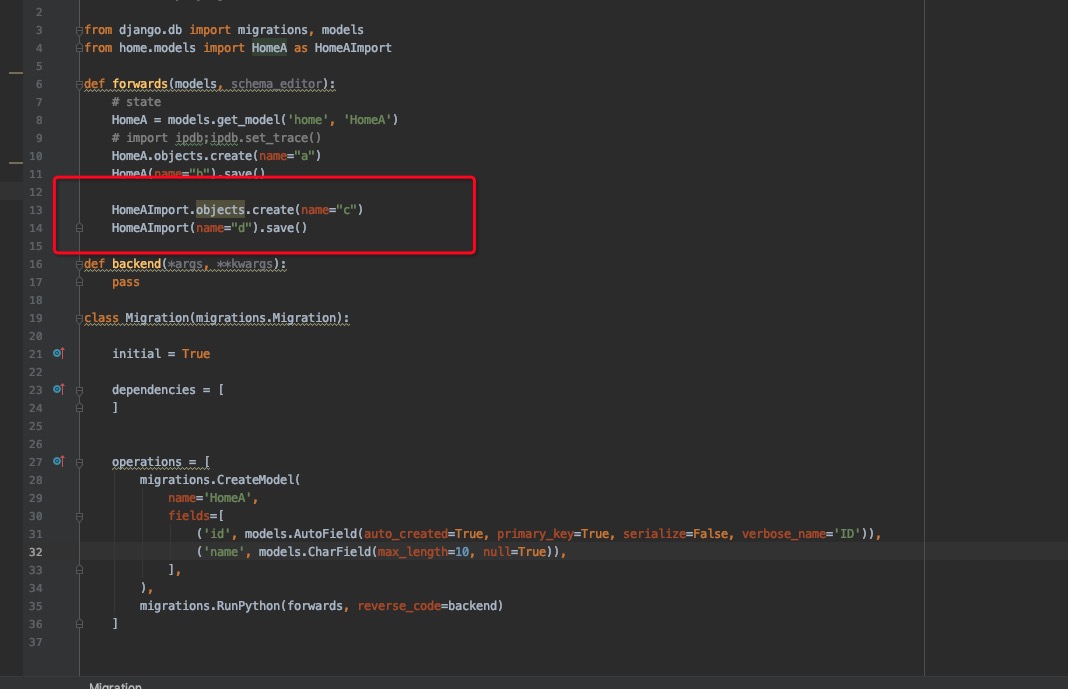
简单描述就是:
migration/001.py执行了插入动作,如上图红框所示,后台一位同学使用import模型的方式执行了一段python代码,简单来看这里insert没有任何问题,而报"Unknown column 'age' in 'field list'"这个错误是因为age字段是在migration/001.py之后才创建的,线上代码更新时那么导入的模型是有age字段的,而数据库是没有这个字段的。插入的时候没有给age值,所以django认为age这个字段是应该存在的,但是数据库实际没有age字段,所以出现了这个问题。
其实这里应该有三种解决方式的:
age字段做任何操作,那么理论上来说这条语句应该通过的,如果通过不了,那应该也是sql语句本身除了问题,不过这个不是这么实现的,所以这种方式我只假设是可以解决这个问题的。ModelState的概念来解决这个问题。(而我们系统没有这个概念,所以改写成裸sql的方式。。。)所有代码均在django/db/migrations文件夹下。
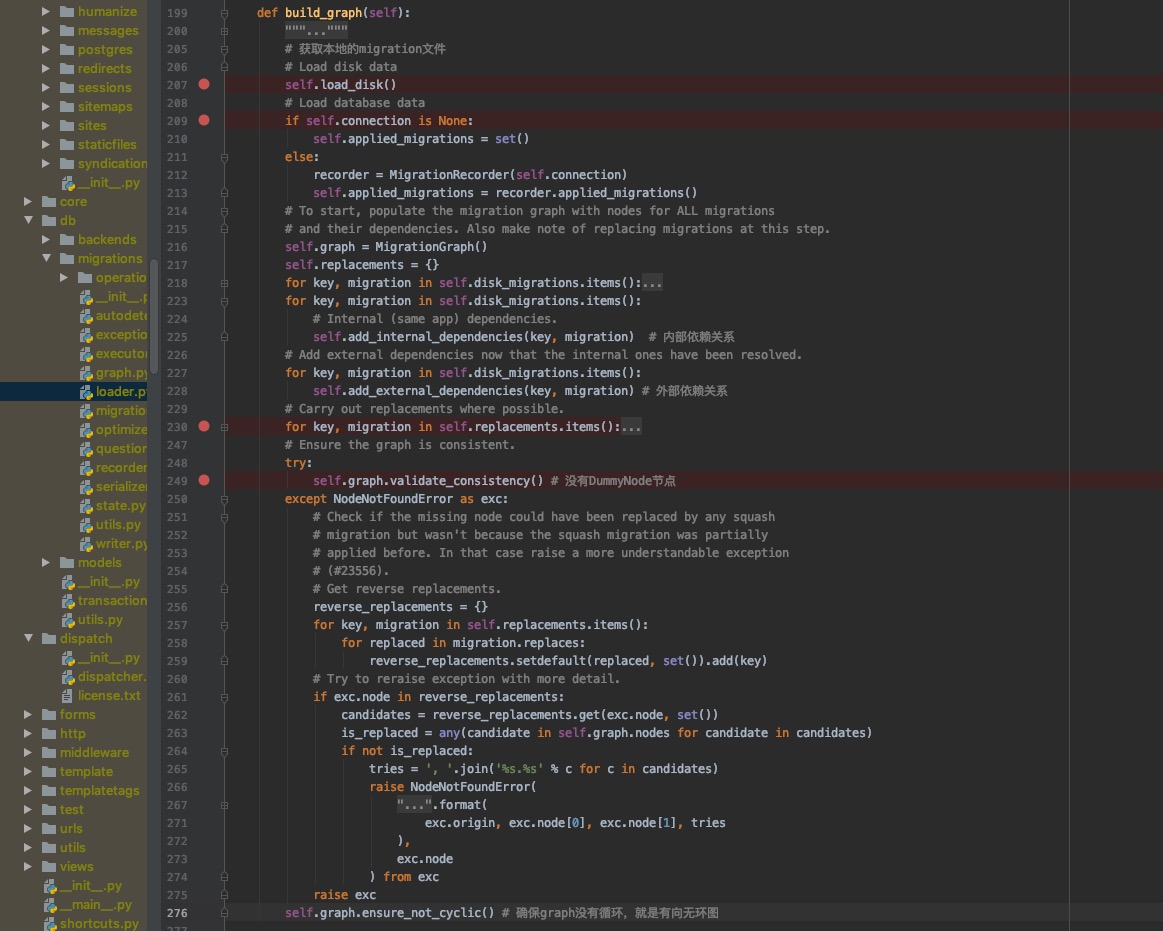
self.load_disk()就是查找项目里面所有的migration文件,然后保存到disk_migrations变量里面。
整个感兴趣的,在于这个MigrationGraph,这个为有向无环图,四个for循环构造出disk migrations所有的信息,然后是一些校验。
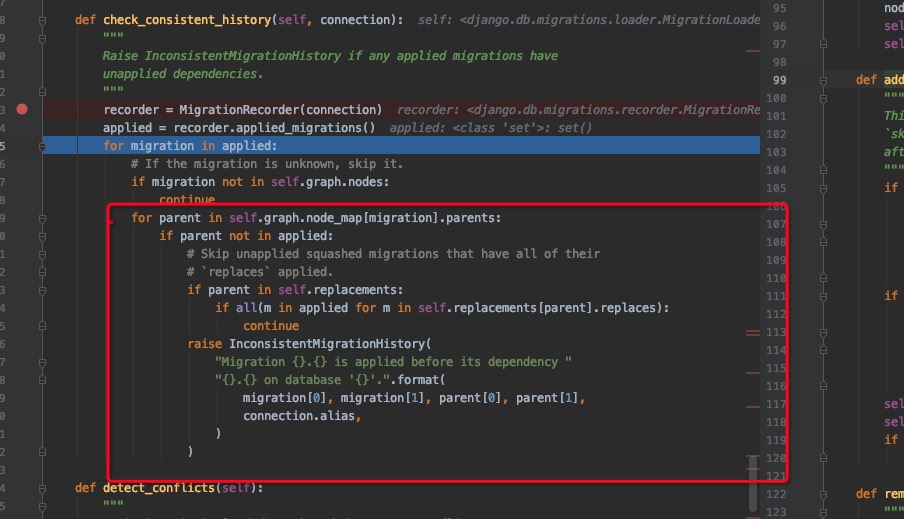
这里检查的已经保存到数据库的记录的parent是否在graph nodes里面,如果没有,则非一致性,那么则报错。
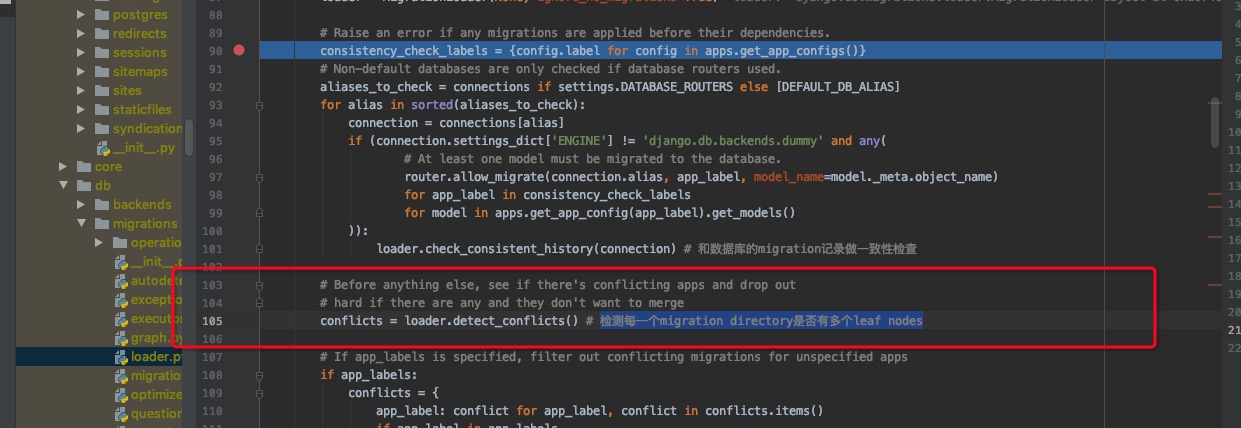
如果有多个leaf nodes, 那么则是否merge,合并到一起。
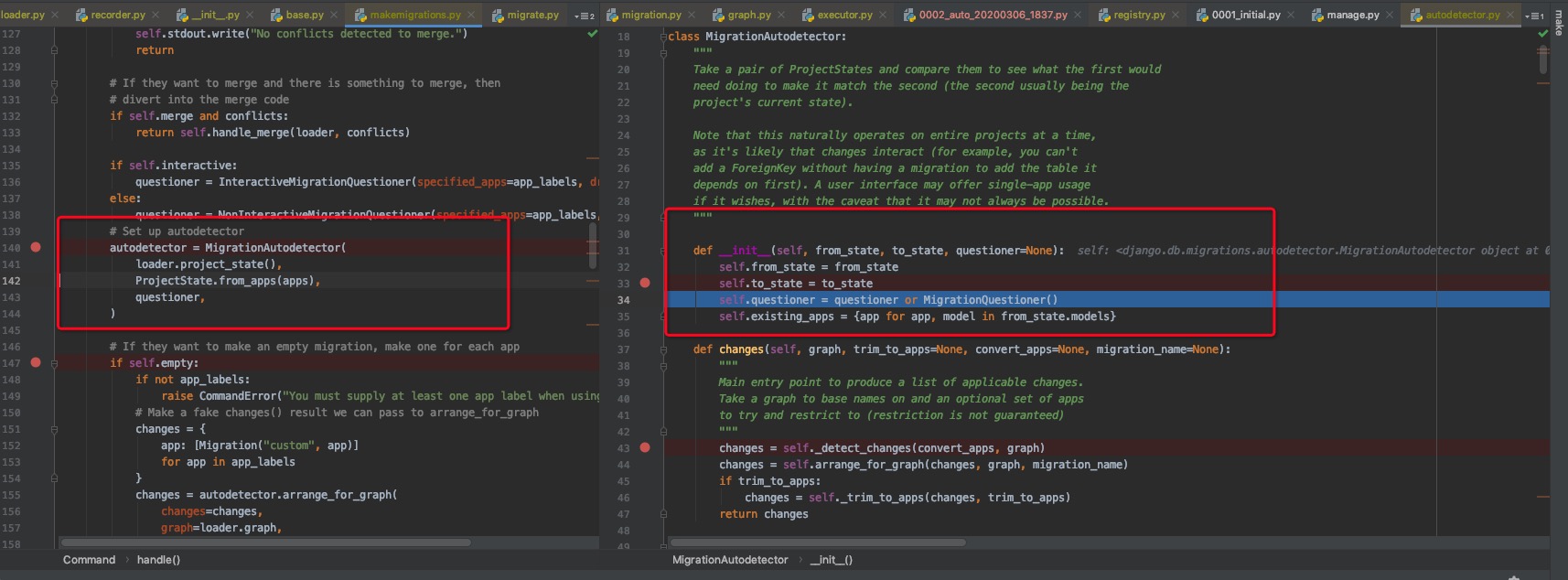
django会根据graph和数据库migration_history
的记录生成两个ProjectState,那么最终比较这两个ProjectState的不同。
而在生成ProjectState的时候,有一步叫做self.graph.make_state(),如下图
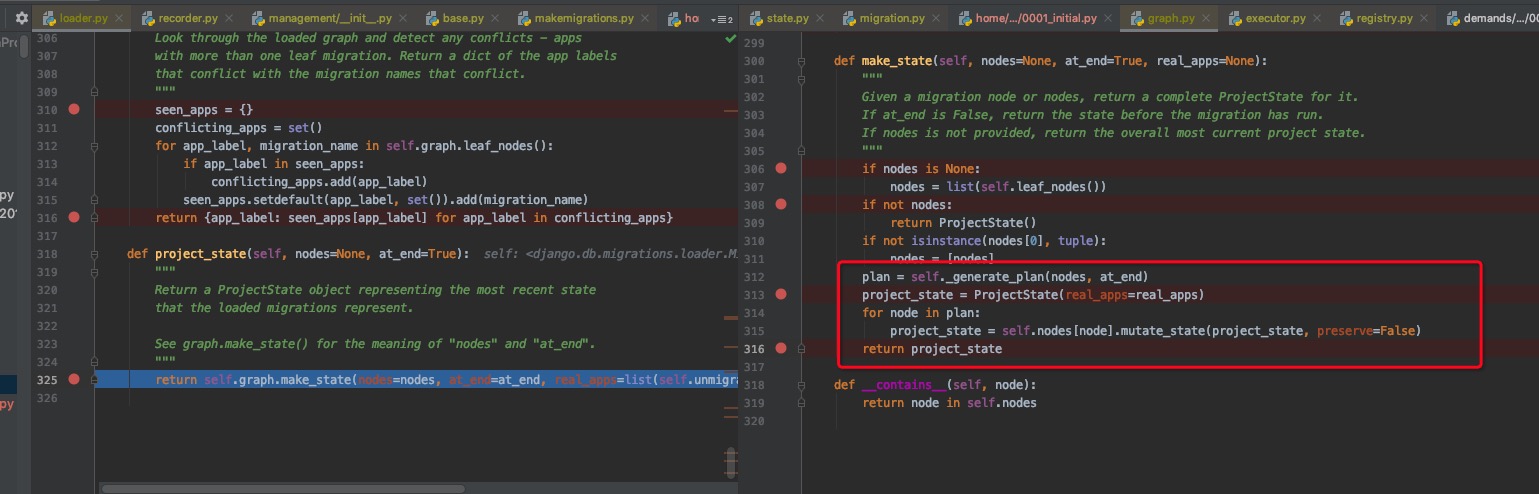
这一步会根据disk migrations生成的graph,然后根据leaf nodes通过dfs进行遍历然后生成ModelState,所以在这里age字段不会在001.py存在的。(这个地方就是django解决代码更新的地方。6啊)
所以下一步就是如何做diff操作,然后生成新的migration文件,简单如下图所示,此处忽略。
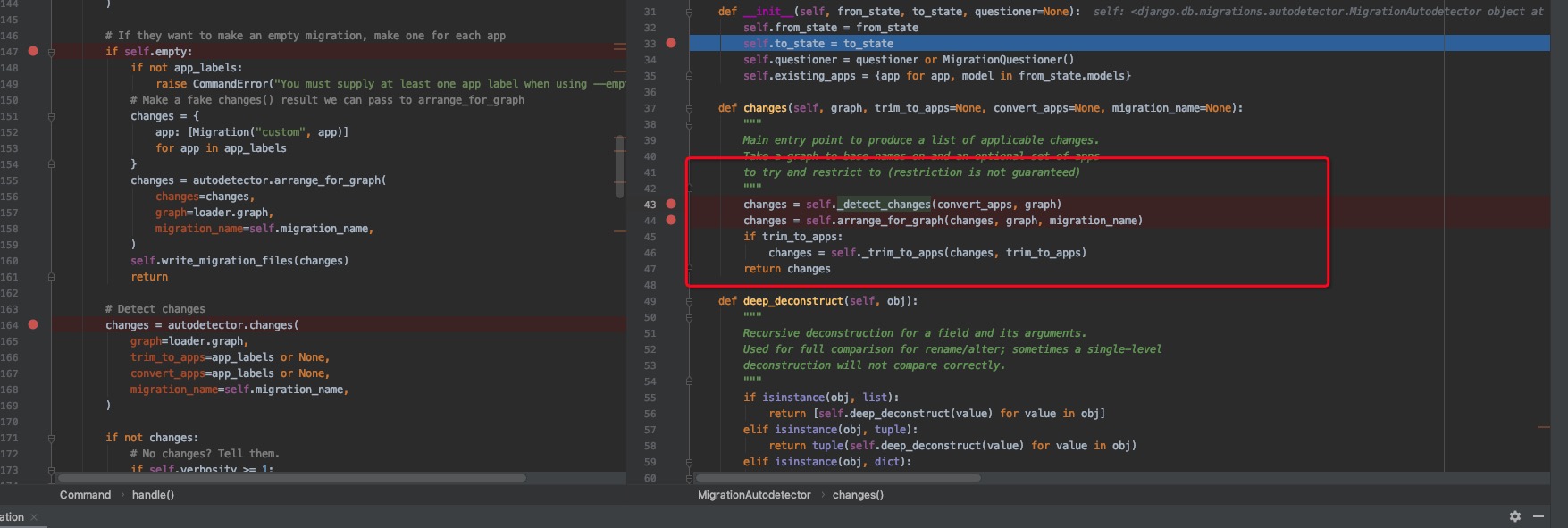
简单来讲,django使用MigrationGraph构造出disk migration和database migration,然后根据sorted(migration)构造出时间线,获得ProjectState以及相应的ModelState,所以在做migrations.RunPython方法的时候,传入的参数models即为相应对应时刻的ModelState,从而避免了代码更新而miration未及时更新导致在orm层面做些操作的时候导致的问题。重点可以看看Graph这里以及如何构造State的。其余自行理解。后面migrate也是类似,以后慢慢讲。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true