简介
DPO全称Direct Preference Optimization,它是RLHF算法的一种,相比PPO算法来讲,它只需要actor和ref model,少了critic和reward model。其核心期望为good loss - bad loss越来越大, 这点和排序模型中的rank loss很相似,但是又不希望和ref model偏差太多。
最小实现代码
1 |
|
DPO全称Direct Preference Optimization,它是RLHF算法的一种,相比PPO算法来讲,它只需要actor和ref model,少了critic和reward model。其核心期望为good loss - bad loss越来越大, 这点和排序模型中的rank loss很相似,但是又不希望和ref model偏差太多。
1 |
|
值函数希望学习一个价值函数,这个值可以用于评估当前决策的分值。策略函数希望学习一个策略函数,拿到其动作的概率分布。
Actor-Critic是在策略函数的基础上,额外引入学习价值函数,来帮助策略函数更好地学习。
下面这个图很好表示了两者关系。
重点看actor-critic算法中update函数log_probs部分。actor采用策略,critic来进行评价。
这个是RLHF系列中的策略梯度部分,在看了Hands-on-RL和parl两者实现后,感觉整体难度并不是很高,但是当自己从零实现时还是会莫名其妙多一些问题,相比深度学习来讲,还是有蛮多小细节是需要额外注意的。
这里是指learn阶段中的获取最大期望阶段,如下代码所示:
1 | output = self.model(obs_bs) |
在最开始自己实现时,我没有加log进行平滑,发现模型没法收敛(CarPole-v0 reward最大得分为200),一直是8,9徘徊。后来我看了上述实现,发现这里多了个log,这里让我觉得很困惑,因为我觉得这一步是不必要的,原因有以下几个方面:
但是呢,如果不加log这一步,模型就无法收敛。
这里是指在每一次done,产生了一批state、reward、action之后,在进行计算loss时,下一步的reward还要考虑当前步reward的结果,即下一步的reward一定要小于当前步的reward。也就是calc_reward_to_go函数这里。
这里同样也会觉得很困惑,因为如果希望期望最大,那就reward * prob使其概率最大即可。
如果看Hands-on-RL他的实现,不会感到任何困惑,因为他是用for来做的。但是呢,parl的实现在考虑了reward * prob使其概率最大这一步之后,又添加了calc_reward_to_go函数,从而本来是个离散的东西,强生生的给变成了一个连续状态的事情,关键呢,怎么看都不像是连续的,因为当前步在计算loss时也并没有跟上一步扯上直接的关系。
这一步还好,从理解角度来讲,我会更倾向Hands-on-RL的实现,容易理解。
关于第一点,我的感觉是步子不能迈太大,宁可慢慢收敛,也要比无法收敛更强,例如model部分我尝试改成如下:
1 | class PolicyNet(torch.nn.Module): |
即forward部分不用softmax,剩下代码保持不变,也同样处于无法收敛状态,似乎来看,softmax+log才是这个算法成功的关键。
这里让我想到一个事情,在深度学习Layer参数初始化的过程,比如:
1 | a = nn.Linear(2222, 11) |
我们会是这么写,基本不会关心a这个linear的参数是如何初始化的。是因为框架内部已经考虑了kaiming、xavier、uniform等各种初始化技术。如果不加这些参数初始化技术,模型基本也很难收敛。
所以如果应用的话,可以采用现成的实现,如果研究的话,其中一些细节可以慢慢调整。
1 | import random |
下面记录下DQN算法以及一些细节,注意哦,本博客更多目的在于当下记录,并非完整严谨的哦,也或许有理解错误。
关于DQN,看了下网上的介绍以及从Q-Learning到DQN解决state和action无法枚举完的情况。另外也强烈推荐下面链接:
看下面这个DQN网络,你觉得有问题么?
1 | class DQN(nn.Module): |
啊啊啊,这里为什么要加softmax呢,是不是习惯了深度学习那套分类思想,再好好想想这里,是不是不应该加softmax。
仔细观察下面代码,eps是在做sample时起作用的,也就是select_action这里,可以看到,在每个epoch结束时,更新新的eps值,从最开始的1,到最后的eps_end=0.1,它是一个比较平滑的曲线。
从select_action可以观察到,action早期处于随机采样的状态,随着epoch的增加,action的决策更多过度到model决策。
那这里是否是必须的呢?
不,这里并不是必须的,因为完全可以在train之前加一个warmup步骤,让model一定程度上学会state到action这个变化。再到后面,就是正常训练流程,不需要sample这个过程了。
那这里更多起到什么作用?
我觉得有个点可以很好理解这里,即从完全小白到慢慢学习直至认知理解的过程。添加warmup,即先提前产生一批训练样本,而eps这里,即随着过程慢慢学习,不过相比warmup,可以更优采取权重随机采样方案,即torch.multinomial(torch.softmax(self(obs), dim=-1), 1).item(),它表现出来的特点是权重高的多次采样出现的频率也会更高,那么随着模型的优化,采样更优的可能性也会提升。
不,这里也并不是必须的。观察整个过程,policy_net要比target_net新一个epoch,而且他俩实际上是在干同一个事情,那么可以将target_net指向policy_net,可以发现epoch的增加,reward的值也是正常提升的。
reply memory可以说记录了整个state和action等的过程,当然有一个maxlen来限制其大小,过早的数据就不要了。
不过需要指出的是,改动了上面这些点,虽然也可以收敛,但是可能会收敛变慢。
这里借鉴了知乎网友实现DQN。
pygame==2.1.0
1 |
|
大模型最近很是火啊,媒体铺天盖地的宣传,候选者简历中写LLM微调等等。本文希望以huggingface trl/RLHF notebooks讲到的几个例子作为入口,介绍下RLHF在整个训练工作中的位置以及起到的作用,方便理解与后续应用。
在huggingface trl/RLHF notebooks这个文件夹下,一共有三个例子:
同时也按照上述这三个文件顺序进行分析。
目的:这个文件实现的是如何利用RLHF学会生成正向评论。

数据集默认有两个字段,text 和label,即用户对一部电影的评论和这条评论的情感倾向(正向、负向)。
这里对text字段随机截断长度为n后面的文本,例如:text=这个电影我觉得很棒。 截取后变成query=这个电影。
这里采用GPT2作为训练model,ref model和model是一样的,可先理解成model是用来训练的,ref model是用来参考的。
ref model是RLHF训练过程中不可缺少的一部分,也跟在generation model后面添加ValueHead层是一个道理,关于强化学习更细力度,本文先忽略。
这里采用distilbert-imdb模型来作为打分模型,这个模型的作用是输入一条评论,它会给出positive、negative的打分。
即让model基于query生成指max_new_tokens的文本,然后让reward model来打分,以positive score为目标,不断优化model,使其能够基于用户给定的文本开头来生成正向评论。
这里的max_new_tokens也比较有意思,它可以有两层的不同解释:
关于后者,我觉得会是一个比较有意思的点。在RLHF中,有针对每一步给一个score,还有走完后针对整条路径给一个score。那这里的max_new_tokens是不是就可以理解成是中间的状态~
既不会因为每一步都打分造成训练效率低下也不会因为对整条路径打分导致某些点决策失误所带来的更大偏差,尽量缓解这种情况。
结束。
目的:通过添加prompt来控制生成评论的情感。

这里的prompt有三类:positive、negative、neutral。由于neutral是reward model本身能力所不具备的,看到这里也可以跳过。
其构造示例如下:
1 | query="[positive]这个电影很" |
那么预期目标是好。
如果是
1 | query="[negative]这个电影很" |
那么预期目标是不好,差之类的情感。
剩下流程和上面文件一致,此处忽略。
目的:RLHF的目标是超越原有天花板,那这种是选取ref model的best of n来和RLHF训练后的做个比对。
整体下来,reward model占据很重要的作用,决定了RLHF的效果,需要注意。
更多看下原代码,整体流程不是很复杂。又水水水了一篇。
以ChnSentiCorp作为情感分类数据集。
train_score.py
1 |
|
训练后F1能达到95%,所以打分模型至此结束。
1 | import pandas as pd |
1 | from transformers import AutoModelForCausalLM, AutoTokenizer |
使用RLHF训练后的生成结果示例如下:
1 | 这个电影,见证点深的艺术价值。<|endoftext|> |
前两个例子还好,比较容易生成理想的正面评论,第三个和第四个例子前面说到了天气很差和屏幕很差,都是偏负面的评论,但是后面生成的文本还是能生成正向的回答,说明经过强化学习的确有产生预期效果。
关于文本流畅问题,有个问题是Wenzhong-GPT2本身产生通顺句子的能力就比较弱,但经过多轮训练,也能产生除生成正向评论外的效果,这点也是很nice.
阿里出了个qwen1.8B,对于资源有所要求的场景或者需要支持长文本的场景,应该是目前国内在这个量级内最优的选择了吧。接下来以此来打通微调、部署各个流程,算是一次记录。
首先按照要求和快速使用来跑起来,安装flash-attn,先跑下推理,正常,接下来就进入微调阶段。
按照微调流程,这里采用LoRA进行微调,但是需要注意的是,虽然官方给出了显存占用及训练速度,但是我在1080Ti上得到的显存占用还是要更高一些,大家可以将这个指标理解成为运行起来至少需要的显存,在进行训练时,还是会有一些增高。
训练的话采用finetune_lora_single_gpu.sh默认配置,幸亏我没有采用train,而是使用了dev数据集,7500条数据,8个多小时,,不过整个loss还是蛮正常的,没有出现issue里出现的各种问题。。。

我这里保存到了outout_qwen,下面为调用LoRA微调后的模型。
1 | path = 'Qwen-1_8B-Chat' |
注意的是,如果到此就打算部署的话,也要将adapter_config.json中的base_model_name_or_path正确引用,不过官方也给了合并代码,可以将LoRA和qwen合并到一起。
1 | from peft import AutoPeftModelForCausalLM |
如果需要使用llama.cpp,这里还是建议进行上述步骤合并的,使用llama.cpp也不是很复杂,可按照官方README安装cmake编译安装,后续也不是很复杂,官方提供了非常清晰的使用说明。
1 | mkdir build |
不过需要注意的是,用不用量化或者说要不要做转换,本身上还是要根据转换后的效果和效率来决定的,由于目前我们直接跑在GPU上,后续有机会单独针对llama.cpp尝试深入一下~
Lora,是微软出的一种在低资源场景下进行微调大模型的实现方式,在transformers里有peft这个包进行调用,它通过固定预训练模型权重并只训练新增lora层来实现微调,目前其在比如Baichuan2、ChatGLM上都有相关资料,更多介绍可自行搜索了解。
其简单理解实现方式为,比如qkv的linear为768*768(更大模型可能会更大),那lora通过新增两个linear(lora_A和lora_B),引入一个超参r来降低训练参数量,其伪代码如下:
1 |
|
比如当r设置为1时,是否可以明显感受到训练参数量的变化。
注意:Lora本质只有在微调阶段生效,其加速了微调,但是对于推理阶段不会加速,而且因引入了新的计算会导致推理速度略有下降。
注意,此篇文章通过介绍LoraLinear的实现,来说明Lora的工作原理。
其实现在这里。
LoraLinear继承自nn.Linear,所以是在Linear的基础上进行改动。
Linear的weight不进行训练,这也符合Lora的原理说明。
1 | self.weight.stop_gradient=True |
forward部分,代码如下:
1 | def forward(self, input: paddle.Tensor): |
我们看如果pretrained model和lora不进行merge的时候,其推理是pretrained model先计算,拿到result,然后和lora计算结果进行相加获取最终结果。
对于Parameter Efficient fine-tune,Lora是其中一个实现方式,其他还有比如p-tuning等。但是通过Lora,我们大致理解了从原来直接对pretrained model fine-tune到现在的引入新的参数(比如)来使得我们能用低资源来使用LLM的能力。
书接上文,layoutLM微调FUNSD数据集介绍了layoutlm和layoutxlm如何做named entity recognition,以及多模态-CLIP和多模态-字幕生成介绍多模态是如何融合的,本文继续基于layoutLM系列,基于huggingface document_question_answering来进行debug是如何实现的。
更新:针对layoutxlm在docvqa_zh上的训练代码已经放到document-qa啦。
在这之前,都是在介绍如何处理数据,也即如下代码:
1 |
|
1 | dataset['test'].select(range(1)).to_dict().keys() |
可以看到,默认dataset有如上几个字段,其中query有德语以及英语,后面updated_dataset做了过滤,只保留了为英语的、以及长度小于512的,最终保留字段如下:
1 | updated_dataset['test'] |
反而变简单了,所以咱们也不用再刻意关注dataset了。
其中一条数据如下:
1 | aaa = updated_dataset['test'].select(range(1)).to_dict() |

看看人家,标注的bbox之类的就不要啦,咱要自己搞。。不过这可以理解它是怎么处理滴。
这部分对应Preprocessing document images,也即如下代码。
1 | image_processor = processor.image_processor |
从image_processor进去,最终到apply_tesseract,其代码如下所示:
1 |
|
咱来看下tesseract识别结果:
1 | from PIL import ImageDraw |
识别结果如下:

可以看到,tesseract拿到每个词的识别坐标。
注意:这里忽略了图片本身操作,比如resize、reshape等操作哦
相关的也有:
 |
 |
|---|---|
| 原始图片1 | OCR1 |
这部分对应Preprocessing text data.
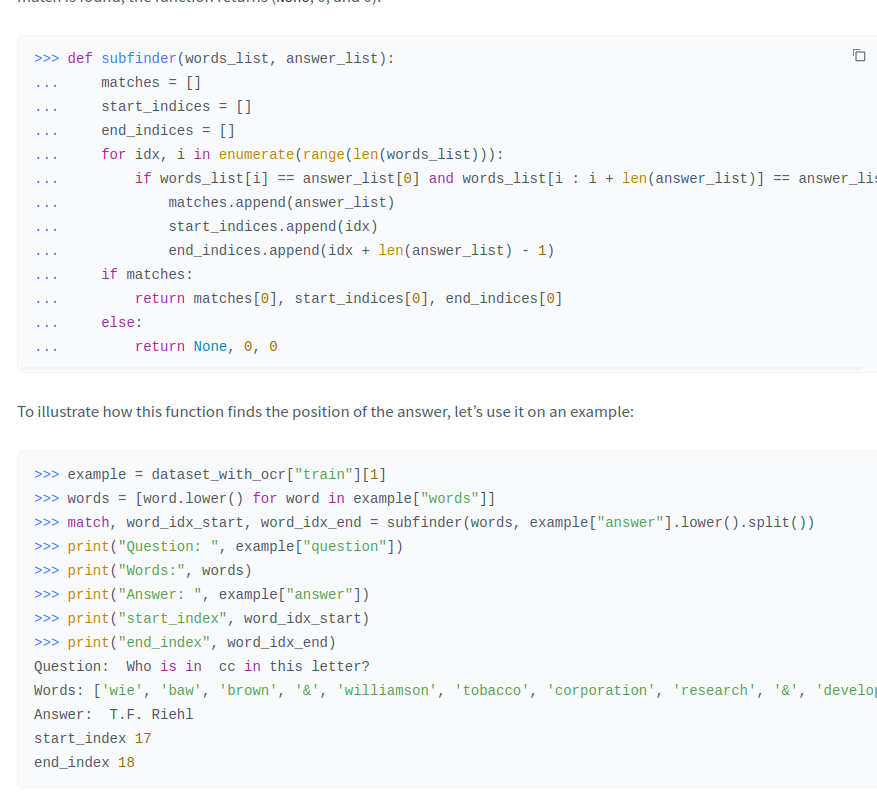
基于上图知道其answer为T.F. Riehl,通过subfinder函数其在原文的位置为start_index=17和end_index=18,通过OCR1图可知其具体位置。
接着tokenizer传入了question,words(ocr原文识别结果),boxes,我们来看其是怎么实现的以及其具体目的。
1 | encoding = tokenizer(example["question"], example["words"], example["boxes"]) |
在这之前,我们可以看到,其具体做的就是encode拿input_ids, attention_mask和token_type_ids,其具体如下:
1 |
|
但是也是从这开始,讲述了bbox是如何跟words对齐的。
其代码如下:
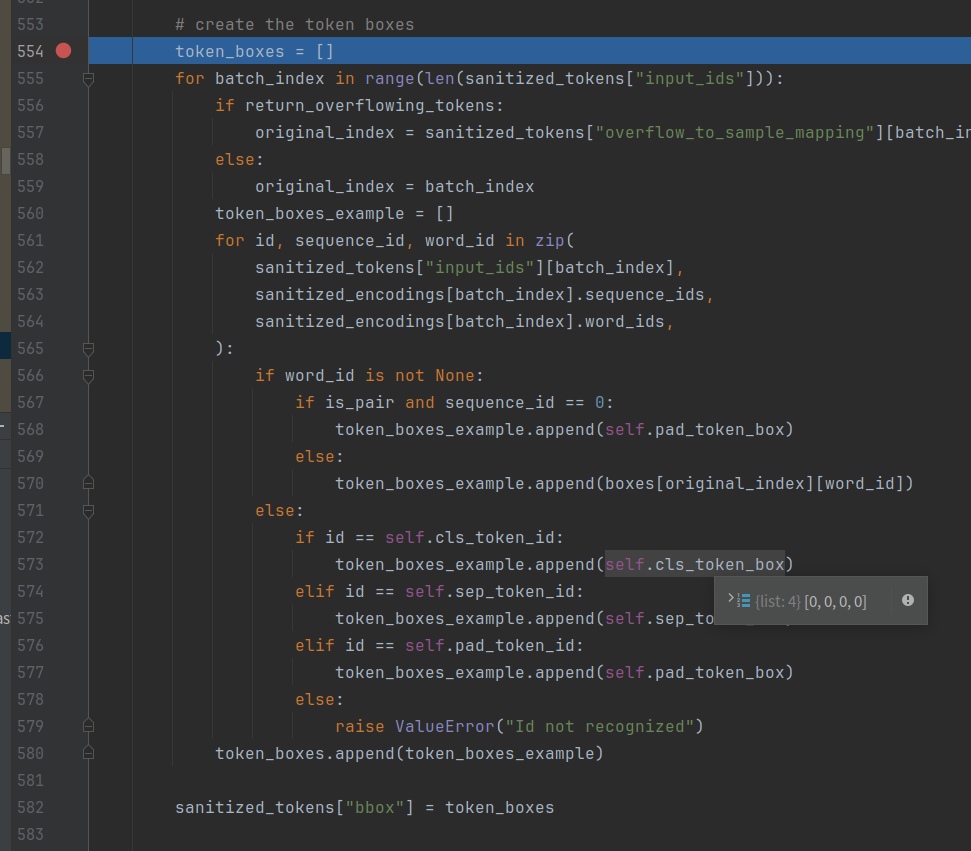
最终生成的结果如下:
1 |
|
着重看上图40~46行,即可明白tokenizer分成subword后,其box按照原词的box进行分配。这个也和原来使用layoutXLM来做是一样的,其在这里。
剩下部分就是encode_dataset函数了,除了和box对齐,另外一个就是基于subfinder函数来找到start_positions和end_positions来作为label。
至此,大致理解了其文本处理方式以及如何和box进行对齐,但是要注意subfinder函数,如果answer没有在words(即ocr识别原文)没有找到,这条数据就废掉了。
模型部分简单如下:
1 | self |
但是一直没搞清楚其visual用的是resnet还是变种,不过这里就忽略了。。。(layoutLMv3用的就是ViT了)。
那接下来我们就一个目的了,看visual feature和text feature如何融合。
这部分反而看的云里雾里,比如为什么生成一个visual_bbox,剩下生成embedding、图像、transformer部分就是常规操作了,先忽略。
这种双指针的方式可以解决一部分文档问答问题,但是针对表格之类的,比如:
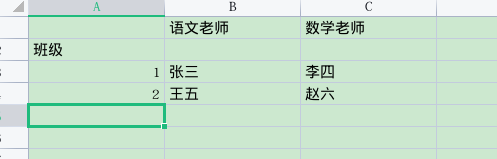
Q1: 班级1班的老师的姓名?
Q2: 班级1班语文老师的姓名和数学老师的姓名?
即一个表格中多个答案和一个疑问句中多个疑问点,就造成这类模型的是无法满足的。
在上一篇文章多模态-CLIP,介绍了CLIP中text跟image如何匹配。本文介绍如何基于image来做字幕生成,也即Image Caption,属于text-to-image任务。
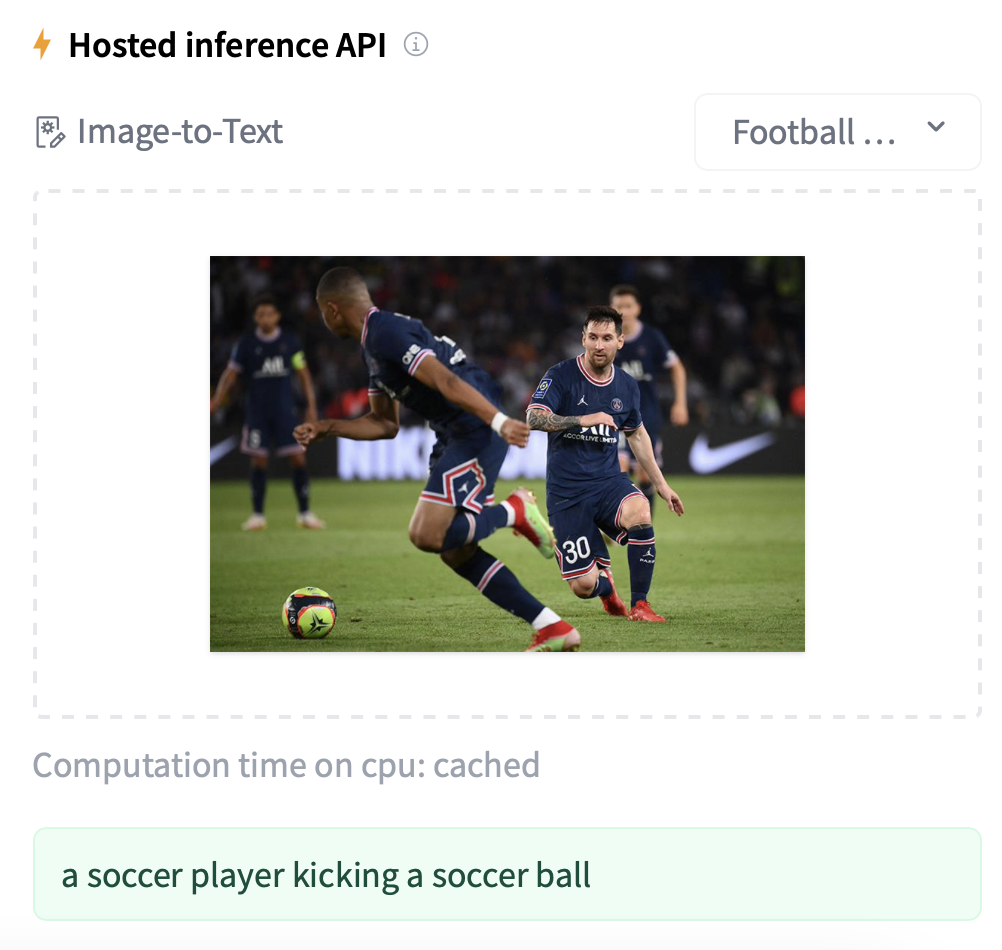
其整体流程用到了transformer/vision_encoder_decoder架构,即使用ViT来作为图像的encoder,gpt2来作为文本的decoder。当然你也可以使用其他模型,整体架构如下图所示。

1、zero_nlp vit-gpt2-image-chinese-captioning
2、The Illustrated Image Captioning using transformers
多模态如何做融合,本文是对CLIP模型理解做个记录。
目前业界有中文开源版本的,例如Chinese-CLIP以及IDEA/Fengshenbang-LM太乙系列,本文采用Chinese-CLIP来梳理其流程。
数据集采用wukong-dataset,预训练模型使用chinese-clip-vit-base-patch16来进行实验。
1 | import pandas as pd |
基于ChineseClip官方说明,知道其text-encoder部分都使用了chinese-roberta-wwm,另外一个可验证点是其vocab.txt的md5值和chinese-roberta-wwm是一样的。所以文本处理,就是找了中文版的bert来做中文的支持,故这部分到此就结束啦~
1 | import pandas as pd |
其流程如下所示,包括转RGB、resize、rescale、normalize、然后转CHW通道。
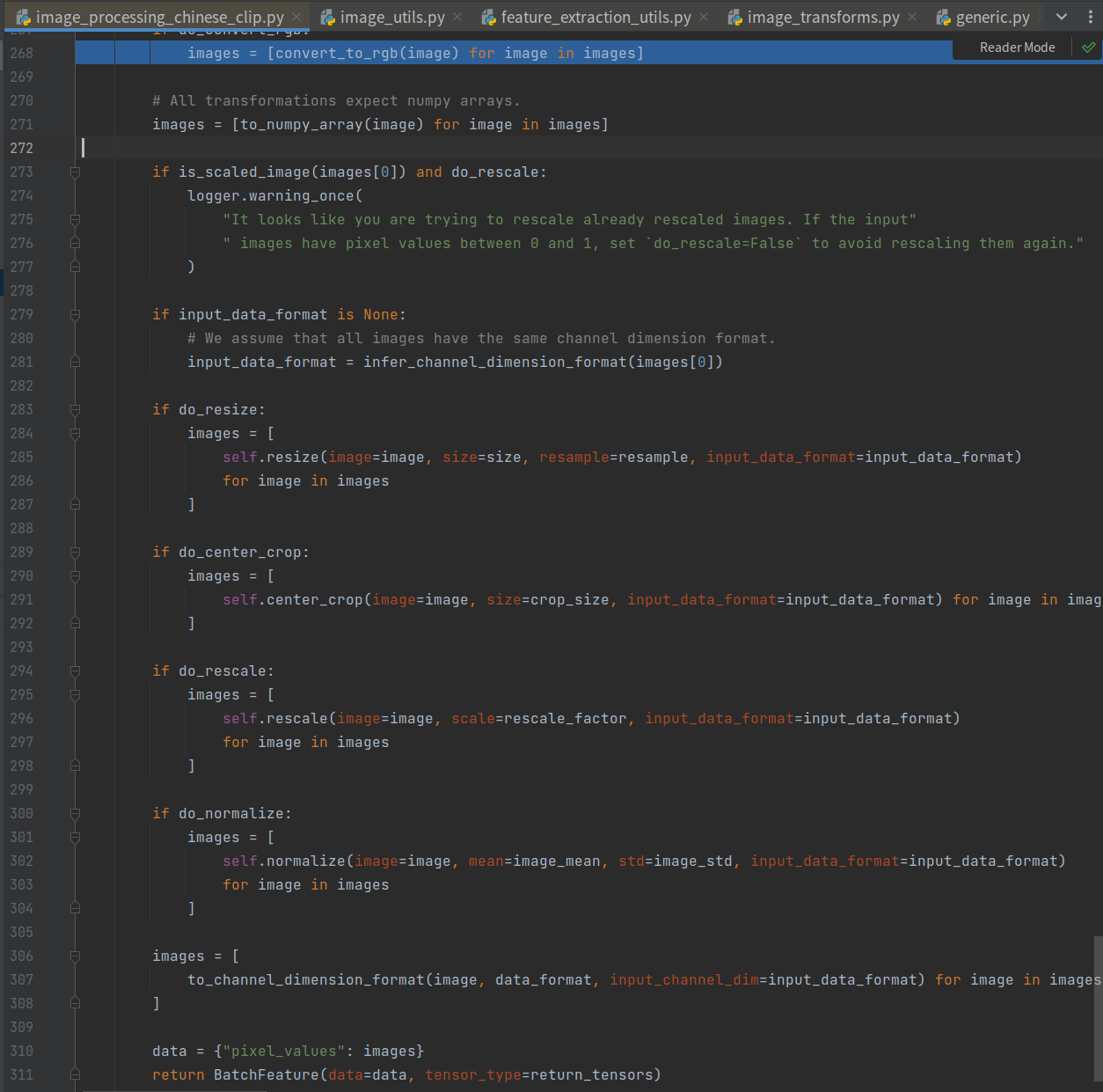
注意resize那里将图片调整为(224, 224),这里对后面处理有用。
重点来喽~
其整理流程如下所示。
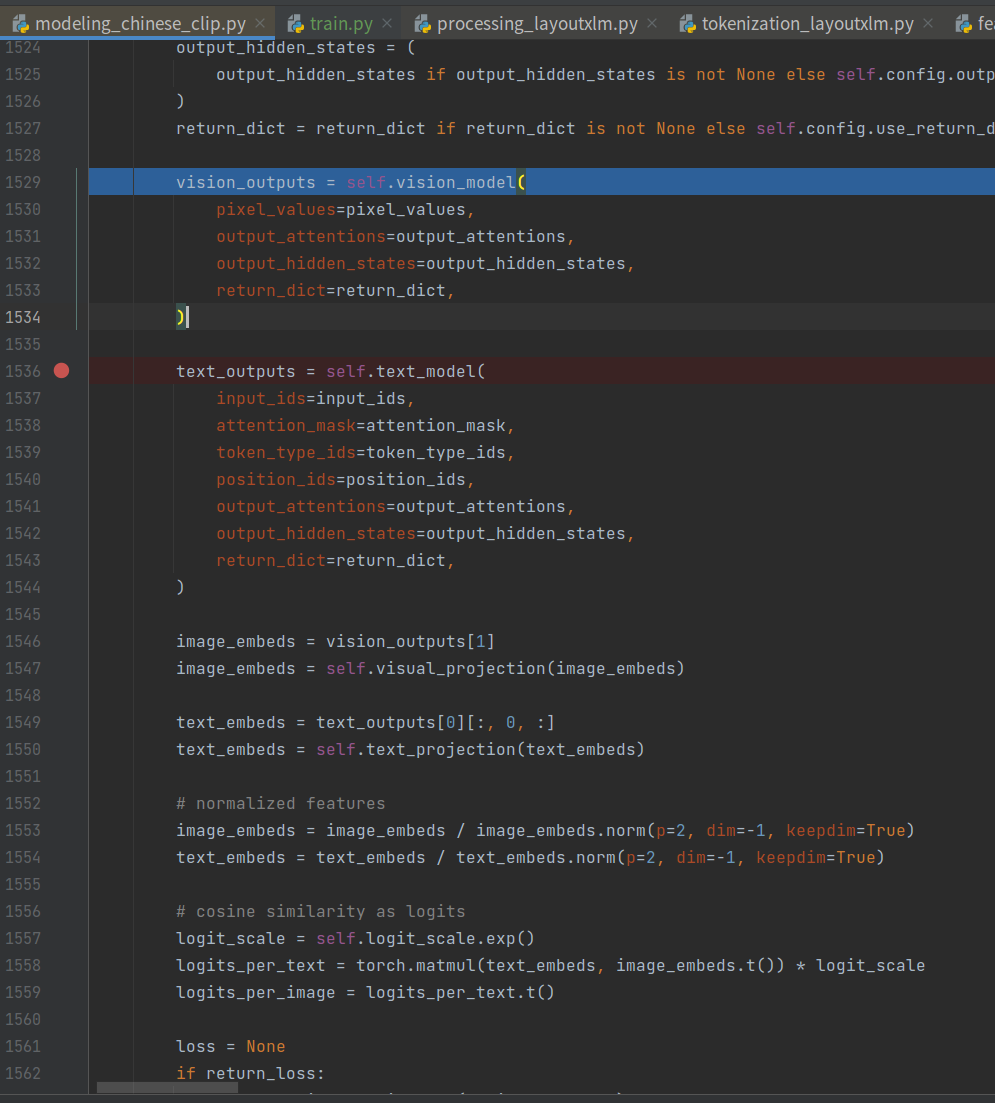
其vision_model下获取embedding如下。
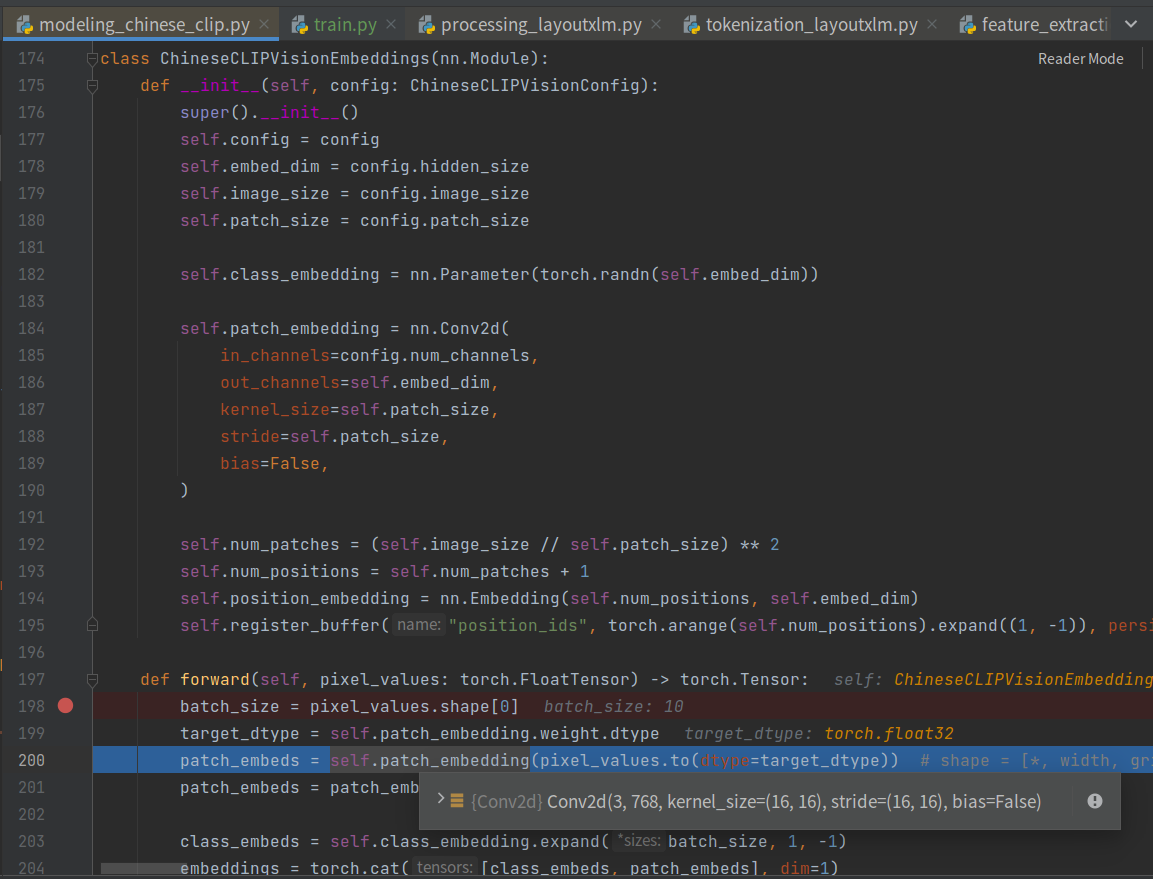
其patch_embeds经过conv2d,转成成了torch.Size([10, 768, 14, 14])(224-16)/16+1,接着
201行代码为:
1 | patch_embeds = patch_embeds.flatten(2).transpose(1, 2) |
14*14=196,最终转换成了(10, 196, 768),到这里就清晰了~
不过在patch_embeds结束后,引入了一个class_embeds,这个就是类似bert中的[CLS]位置,用以做下游分类的。
在拿到vision embedding之后,后面就是encoder部分啦,这里对应ChineseCLIPVisionEncoder,这部分本文先忽略。
这部分就是bert处理流程了,作者也写的很明白,就是bert那一套。
至此拿到vision_outputs和text_outputs,其vision_outputs为:
1 | last_hidden_state=(10, 197, 768) |
其text_outputs为:
1 | last_hidden_state=(10, 64, 768) |
好奇:至此768维已经对齐了,为啥还要各自经过一个self.visual_projection和self.text_projection将其转为512维。。。
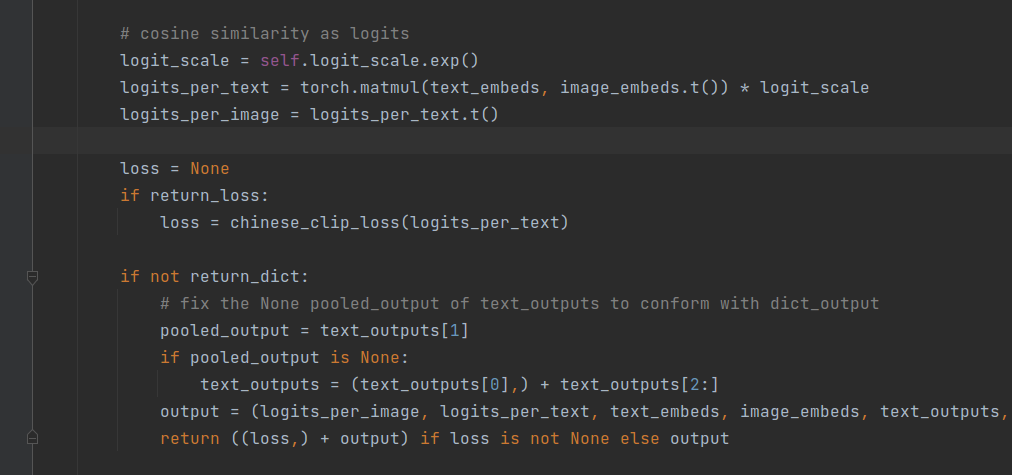
这里处理跟simcse计算loss流程蛮类似的,不过这里计算loss还是蛮有意思的:
1 |
|
正常来讲,我们只需要计算一次即可,这里分别进行计算,也算是一个有意思的点。
至此,模型整体流程大致完成。能够用来基于文本找图像。
1 | # 备忘 |
那是否有一种文本跟图像语义对齐的呢?留给以后~
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true