介绍
Llava是一个多模态大模型,本文以如下代码大致介绍下。
1 | import os |
模型结构
1 |
|
一共三部分:
- CLIPVision负责处理图像部分
- Llama负责文本部分
- multi_modal_projector负责将图像hidden_size投影到Llama一样维度。
数据处理
图像部分走的是CLIP处理流程,resize到336*336,所以pixel_values shape为(3, 336, 336),其他没啥特殊。文字部分走的是Llama,这个就很熟悉了。
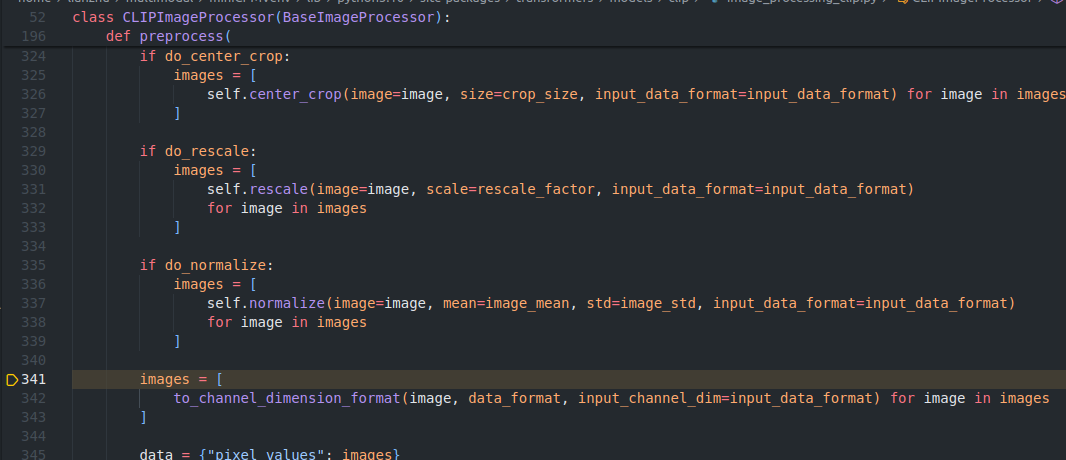 |
 |
|---|
visual和text对齐
image走ViT,kernel_size为14,所以计算过程和结果如下:
1 | (336-14)/14+1 = 24 |
由于CLIP输出是1024,经过multi_modal_projector后维度为(1,576,4096),这个也是下面image_features的维度。
至此同一个维度4096。
image插入位置
原prompt如下:
1 | prompt = "USER: <image>\nWhat's the content of the image? ASSISTANT:" |
<image>是插在指定位置的,那么这里图文对齐和之前的对齐就增添了另外一个含义:不仅要能图文对齐,还要考虑图像插入位置。
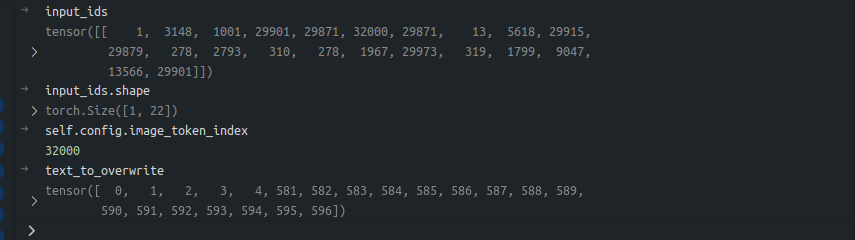
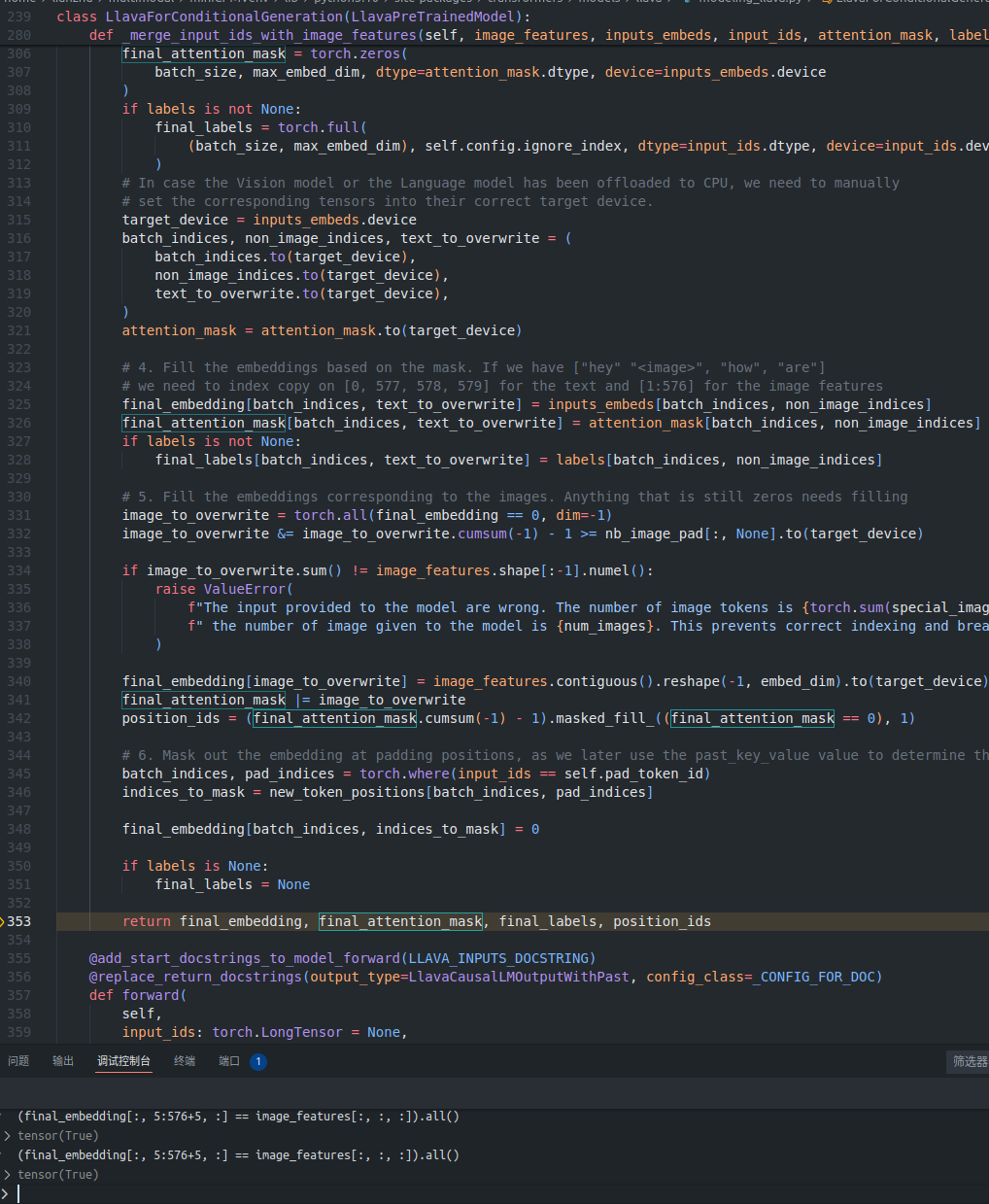
参考上图中_merge_input_ids_with_image_features函数以及结合上图中的信息,那么不难得出如下结论:
1 | (final_embedding[:, 5:576+5, :] == image_features[:, :, :]).all() |
由于后续target task为VQA、Image Caption之类的,先到此为止。
