问题来源
之前线上代码更新的时候报了一个migration类似的错误,报错信息如下:
1 | django.db.utils.OperationalError: (1054, "Unknown column 'age' in 'field list'") |
出现错误的代码模型文件为:
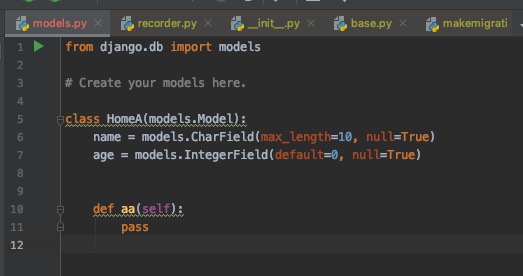
出现错误的代码对应的migration/001.py文件为:
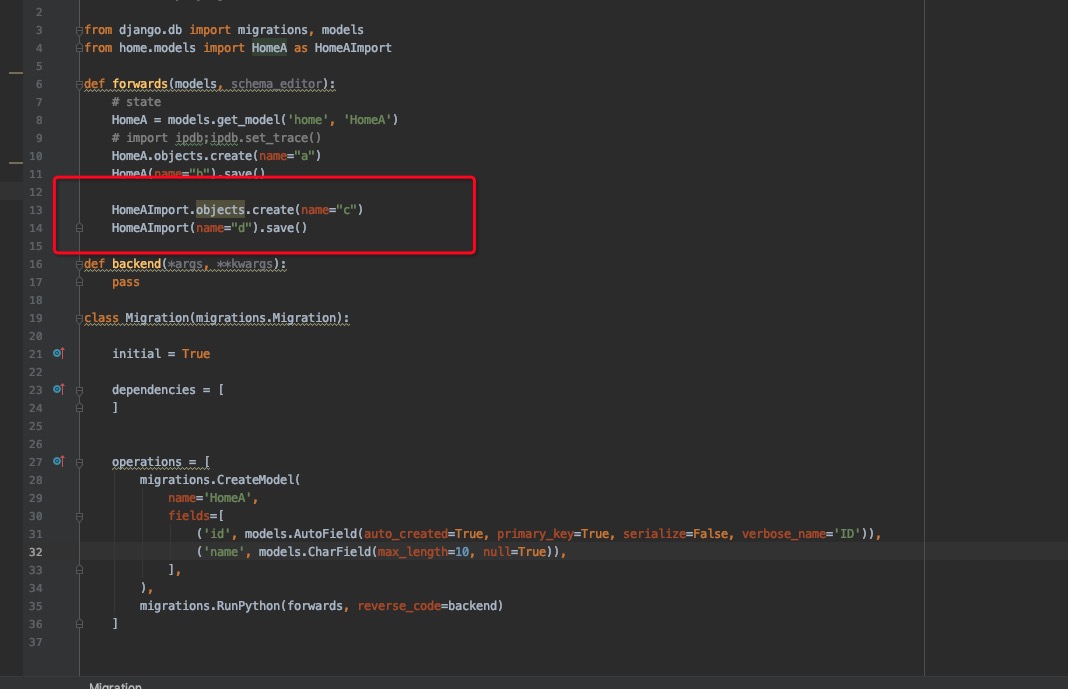
简单描述就是:
migration/001.py执行了插入动作,如上图红框所示,后台一位同学使用import模型的方式执行了一段python代码,简单来看这里insert没有任何问题,而报"Unknown column 'age' in 'field list'"这个错误是因为age字段是在migration/001.py之后才创建的,线上代码更新时那么导入的模型是有age字段的,而数据库是没有这个字段的。插入的时候没有给age值,所以django认为age这个字段是应该存在的,但是数据库实际没有age字段,所以出现了这个问题。
解决方式
其实这里应该有三种解决方式的:
- 在migration/001.py并没有对
age字段做任何操作,那么理论上来说这条语句应该通过的,如果通过不了,那应该也是sql语句本身除了问题,不过这个不是这么实现的,所以这种方式我只假设是可以解决这个问题的。 - django引入了
ModelState的概念来解决这个问题。(而我们系统没有这个概念,所以改写成裸sql的方式。。。) - 直接将模型引入到migration文件内(不过这个如果有外键或者python文件很复杂的话就不如写裸sql了,虽然有时候裸sql也很难写。。。)
漫谈migration
所有代码均在django/db/migrations文件夹下。
先看makemigration的实现方式
首先初始化MigrationLoader实例,第一步执行build_graph函数,如下图所示。
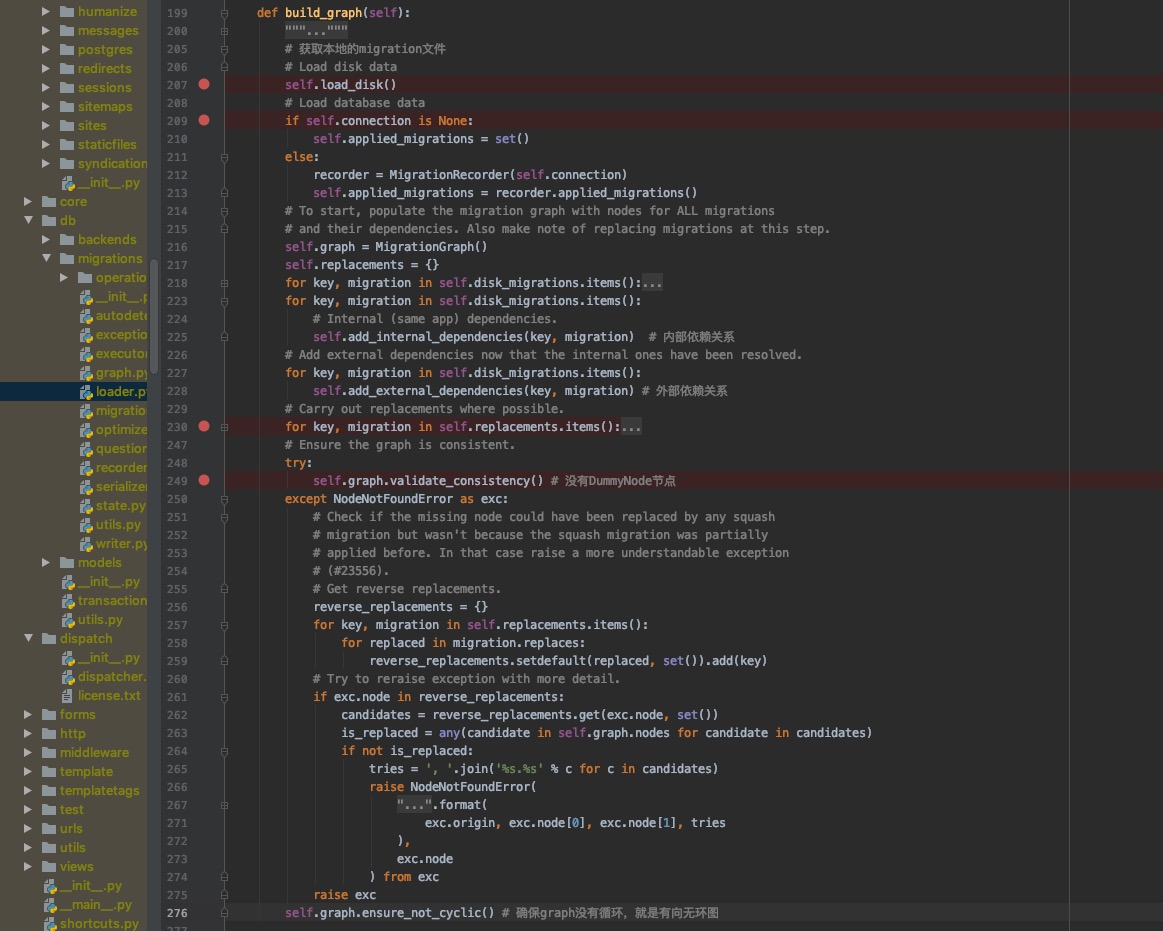
self.load_disk()就是查找项目里面所有的migration文件,然后保存到disk_migrations变量里面。
整个感兴趣的,在于这个MigrationGraph,这个为有向无环图,四个for循环构造出disk migrations所有的信息,然后是一些校验。
检测迁移历史记录的一致性
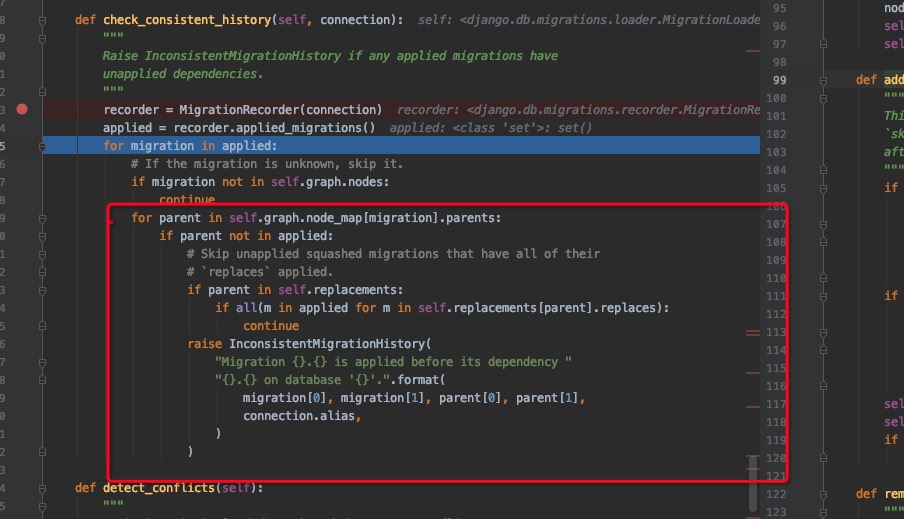
这里检查的已经保存到数据库的记录的parent是否在graph nodes里面,如果没有,则非一致性,那么则报错。
检测每一个migration directory是否有多个leaf nodes
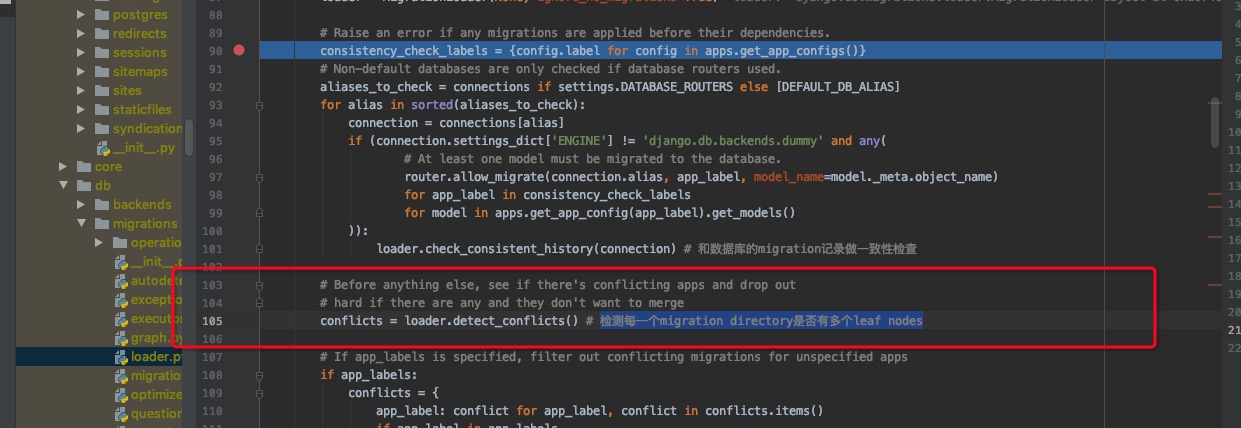
如果有多个leaf nodes, 那么则是否merge,合并到一起。
至此,该检查的也检查了,剩下一步就是如何做diff操作,然后生成新的migration文件。
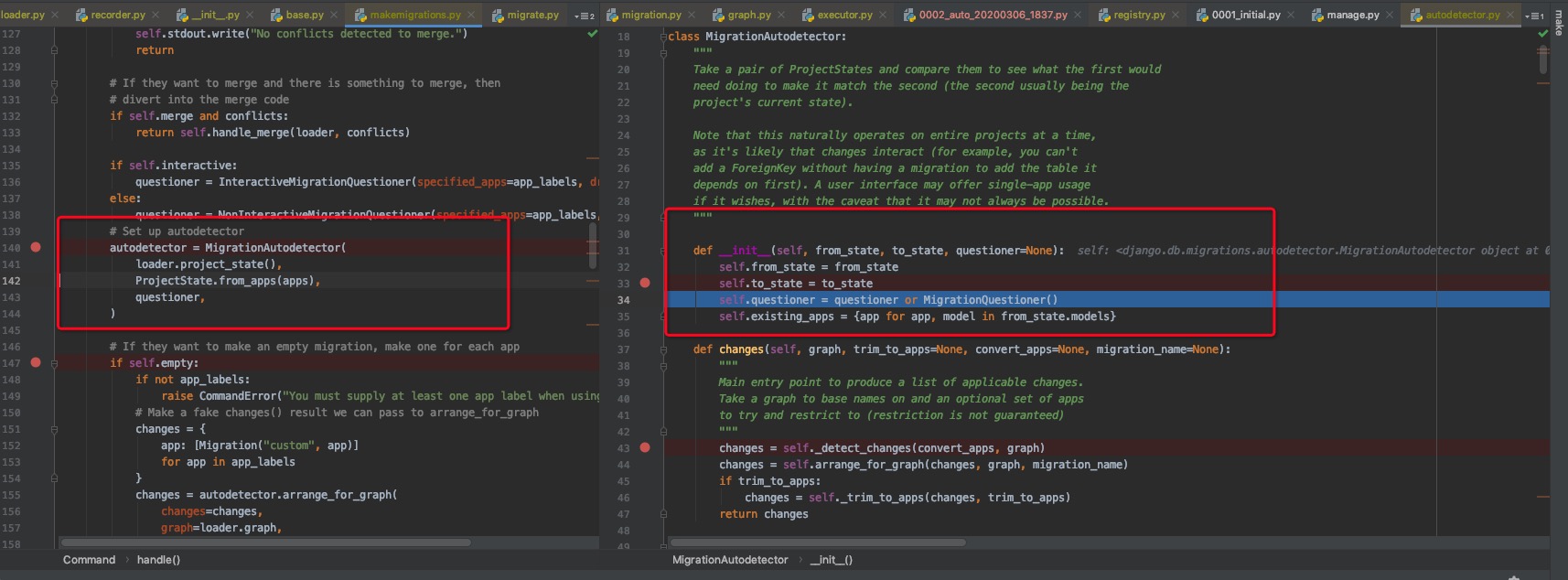
django会根据graph和数据库migration_history
的记录生成两个ProjectState,那么最终比较这两个ProjectState的不同。
而在生成ProjectState的时候,有一步叫做self.graph.make_state(),如下图
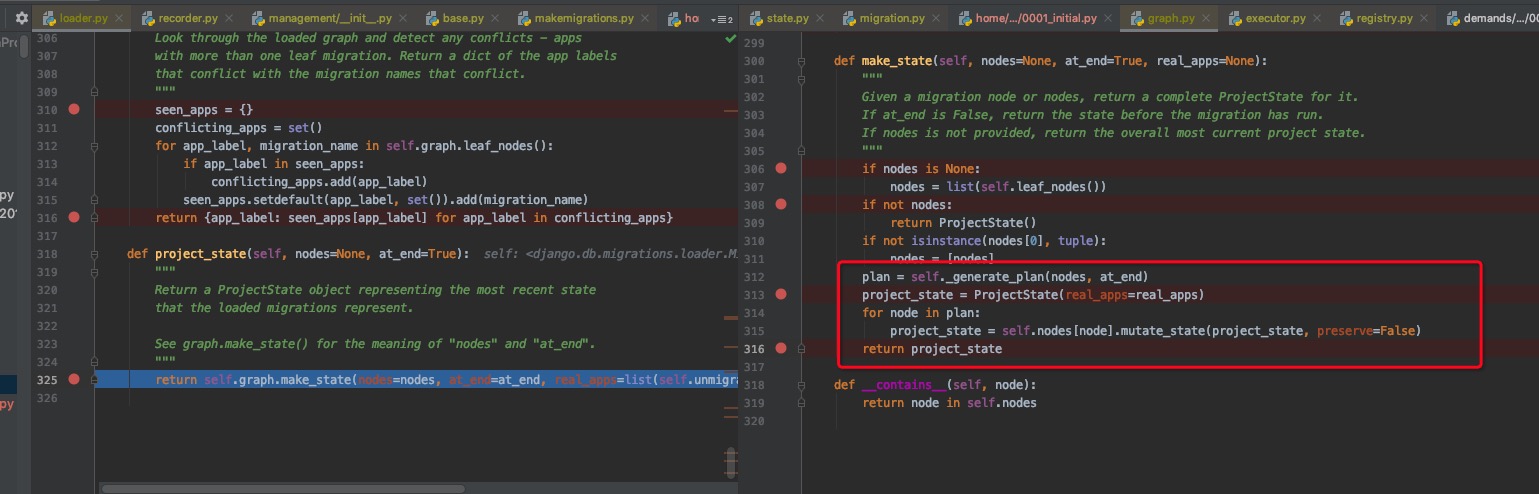
这一步会根据disk migrations生成的graph,然后根据leaf nodes通过dfs进行遍历然后生成ModelState,所以在这里age字段不会在001.py存在的。(这个地方就是django解决代码更新的地方。6啊)
所以下一步就是如何做diff操作,然后生成新的migration文件,简单如下图所示,此处忽略。
后记
简单来讲,django使用MigrationGraph构造出disk migration和database migration,然后根据sorted(migration)构造出时间线,获得ProjectState以及相应的ModelState,所以在做migrations.RunPython方法的时候,传入的参数models即为相应对应时刻的ModelState,从而避免了代码更新而miration未及时更新导致在orm层面做些操作的时候导致的问题。重点可以看看Graph这里以及如何构造State的。其余自行理解。后面migrate也是类似,以后慢慢讲。
